Contents
시계열 분석은 다양한 분야에서 사용되고 있다. 단순히 사용자 출입 로그나 행동에 대한 분석을 하는 것도 시계열 분석으로 접근할 수 있다. 시계열 분석은 기본 통계 모델인 ARIMA와 딥러닝 기반인 RNN, CNN+LSTM 등 모델이 존재한다. 딥러닝이 최신 기술이라고 예전의 전통적인 통계모델을 무시할 수 없다. 일반적으로 이상치가 존재하지 않는 경우에는 ARIMA 등 전통적인 모델의 성능이 더 잘나올 수 있다. 즉, 패턴이 명확한 데이터의 경우에는 머신러닝 기법을 사용하는 것이 일반적으로 성능이 좋으며, 패턴이 복잡한 경우 일반적으로 딥러닝 기법을 사용하는 것이 성능이 좋다.
시계열 데이터는 '시간의 흐름에 따라 관측치가 변하는 데이터'를 의미하며, 우리가 가지고 있는 데이터에서 시간이라는 속성이 들어가냐에 따라 이를 시계열 데이터로 보는지, 아닌지를 판단할 수 있다. 추천 시스템에서는 소셜 네트워크에서 사용자의 팔로워 수를 시간의 흐름에 따라 기록한다면 이는 시계열 데이터가 될 것이고, 단순히 수치로 현재 팔로워 수를 보여준다면 이는 일반 데이터가 될 것이다.
시간이라는 속성이 추가되는 경우 어떠한 문제가 발생할까? 일반적인 데이터에서 가지고 있는 평균 및 분산이 시간이라는 속성으로 인해 변화하게 되어 패턴을 찾는 것이 어려워질 수 있다. 기존 모형들은 정규분포를 가정해 분석을 시행하기에 기존 모형에 시계열 데이터를 입력하게 되는 경우 오류가 발생할 수 있다. 즉, 기존 모형은 정상성(Stationarity)을 가정하고 있기 때문이다.
시계열 데이터의 속성
시계열 데이터는 일반적으로 추세 성분(Trend Component), 계절 성분(Seasonal Component), 불규칙 성분(Residuals or Irregular Component), 3개의 속성을 가진다고 한다. 추세 성분은 어떠한 추세를 가지고 그래프가 움직이는 것을 의미한다. 계절 성분은 어떠한 패턴을 가지고 반복되는 성분을 의미한다. 불규칙 성분은 추세 성분과 계절 성분을 뺀 나머지 설명되지 않는 성분을 의미한다. 따라서, 이와 같은 성분을 통해 시계열 데이터가 생성된다는 가정으로 진행되며, 수식으로 표현하면 다음과 같다.
\[ y_t = T_t + S_t + R_t \ \text{or} \ y_t = T_t \times S_t \times R_t \]
위 수식을 기반으로 $y_t$에서 각각의 성분을 빼면서 패턴을 찾아낼 수 있을 것이다. 예를 들어, 추세 성분이 들어가게 되면 데이터의 레벨이 변화되는데, 이러한 요인을 빼게 되면 데이터의 평균이 정상성을 가지게 된다.
\[ y_t - T_t= S_t + R_t \]

이처럼, 비정상 시계열을 정상 시계열로 분해하고 난 후 다음 데이터를 예측하기 보다 쉬울 것이다. 정상 시계열로 만들어진 데이터를 이제 모델에 입력으로 사용해 예측할 수 있다. 예측 후 다시 빼준 성분을 더해줌으로써 값을 예측할 수 있다. 이러한 방식이 전통적인 관점에서의 시계열 모델이다.
정상성과 비정상성
그렇다면 정상성(Stationarity)과 비정상성(Non-Stationarity)이라는 말은 무엇일까? 정상 시계열은 시간의 흐름에 무관하게 일정한 평균과 분산을 가지는 것을 의미하며, 비정상 시계열은 시간의 흐름에 따라 변동적인 평균과 분산을 가지는 것을 의미한다. 실제 데이터를 가지고 처리할 때에는 비정상 시계열을 정상 시계열로 바꾸는 경우는 엄청 어렵다. 따라서, 정상성을 두 가지 경우로 나눈다. 정상성은 강한(Strict) 정상성과 약한(Weak) 정상성으로 분류하며, 강한 정상성은 거의 존재하지 않는다. 약한 정상성은 평균은 일정하나 시간에 종속적이지 않고, 분산은 시차에 따라 변하는 것을 의미한다.
자기상관 (Auto-Correlation)
자기상관은 자기 자신의 데이터 간의 상관계수를 본다는 것을 의미한다. 시계열의 구간 간의 상관관계를 본다는 것을 의미한다. 그렇다면 어떻게 자기상관을 계산할 수 있을까? 이때 사용하는 것이 바로 시차(Time Lag)가 된다. 시차 1, 2, 3... 을 적용한 데이터와 시차가 0의 상관관계를 구하면 시차의 변화에 따라 자기상관을 계산할 수 있다.
이를 통해 자기상관함수(ACF)를 만들 수 있다. 이는, 시차에 따른 관측값 간의 연관 정도를 나타낸다. 정상 시계열의 경우 ACF는 빠르게 0으로 감소한다. 약한 정상의 경우 분산이 시차에 따라 변하기 때문에 ACF가 빠르게 감소하는 것이다. 비정상 시계열의 경우 ACF는 천천히 감소하며, 큰 값을 가지는 경우가 많다. 이때 ACF가 뒤죽박죽이 되면 비정상 시계열로 판단한다.
얼마나 빠르게 감소하는 지에 대한 판단은 통계학 관점에서 볼땐 ADF를 통해 p-value를 가지고 검증한다. 해당 시점으로 부터 0으로 수렴한다는 것을 봐야한다. 이를 바탕으로 ARIMA 모델을 돌린다. 약간의 노이즈가 발생할 수 있는데, 이를 사용할 것인지 말 것인지는 연구자의 판단 하에 진행할 수 있다. ADF는 이처럼 노이즈가 얼마나 있는지 확인할 수 있는 통계 판단 지표다.
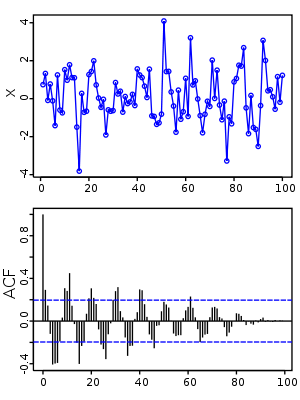
편자기상관함수(Partial ACF, PACF)
편자기상관함수는 시차 사이에 있는 값들을 배제하고 온전히 현재 시점의 값과 K 시점 이전 값만을 고려해 자기 상관을 계산하는 것이다. K=0이라면, K=0은 고려하지 않고 K=1부터 고려한다는 것이다. 만약 과거의 패턴까지 고려하기 위해서는 ACF를 사용하고, 아닌 경우에는 PACF를 사용한다. 예를 들어 1일 부터 5일까지의 데이터가 있다면, 1일부터 4일까지 데이터와 2일부터 5일까지의 데이터를 비교하는 것이다.
변환 (로그 스케일, 차분)
그렇다면 정상 시계열로 변환은 어떻게 할 수 있을까? 그래프의 변동폭이 일정하지 않으면, 분산이 일정하지 않으면 로그를 씌어 분산을 일정하게 유지되도록 변환하는 방식이 있고, 추세, 계절 요인이 관찰되면 차분(Differencing)을 통해 평균이 일정하게 되도록 변환한다. ($y_t = y_t - y_{t-1}$) 위 두 경우를 모두 해당하는 경우 로그와 차분을 모두 수행한다. (순서는 상관없음) 데이터가 음수가 있는 경우에는 min_max 를 해주거나, 어떠한 상수값을 더해서 진행하면 된다.
비정상 시계열에 ACF 를 통해 결과값을 보고, 로그를 씌우거나 차분을 거친 후 다시 ACF 함수를 적용했을 때 정상이 제대로 되었다면 모델에 입력으로 사용하면 된다.
ARIMA
ARIMA(AutoRegressive Intergrated Moving Average)는 전통적인 통계모델 중 하나로 정상 시계열이 입력으로 들어왔을 때는 ARIMA의 성능이 딥러닝보다 성능이 좋다. ARIMA는 AR과 MA를 결합한 모델이므로, AR과 MA를 이해하여야 한다.
AR(Auto Regressive Model)
AR는 과거 관측값을 이용해 현재, 혹은 미래의 값을 설명하는 모델이며, 수식은 다음과 같다.
\[ y_t = c + \phi_1 y_{t-1} + \phi_2 y_{t-2} + \cdots + \phi_p y_{t-p} + \epsilon_t \]
p는 과거 어느정도 데이터까지 사용할 것인가를 보는 것이다. c는 상수를 의미하며, $\epsilon_t$는 이 시점에 에러값이 얼마인지를 설명하는 것인데, 일반적으로 사용하지는 않는다. 시계열이 정상을 띈다면, 회귀 모델의 가정을 충족하기에 회귀 모델의 사용이 가능하게 된다. 일반적으로 AR(p)로 표기한다.
MA(Moving Average Model)
AR는 과거의 데이터를 가지고 분석하는 모델이라면, MA는 약간 관점이 다르다. MA model이라고 부르는 것은 일반적인 MA와는 조금 다르다. 우리가 어떠한 시계열 데이터를 가지고 전처리를 했을 때 이 시계열을 정상 시계열이라고 가정해보자. 그렇다면 이 시계열은 모든 구간에서 동일한 평균과 편차를 가질 것이다. 그렇다면 이 시계열의 모집단 분포도 동일한 평균과 분산을 가질 것이다(정규 분포를 가정).
이렇게 구성된 모집단에서 데이터를 샘플링 한다. 표본 집단(시계열)과 모집단에서 각각 샘플링한 데이터의 에러가 일정할 것이라 가정하고 분석을 진행한다. 이때 모집단을 백색 잡음(White Noise)이라 부른다. 평균이 $\mu$, 표준편차가 $\sigma$인 백색 잡음(White Noise)으로 생성한 시계열과의 error의 조합으로 표현할 수 있다.
\[ Z_t = a_t - \theta_1 a_{t-1} - \theta_2 a_{t-2} - \cdots - \theta_q a_{t-q} \]
$Z_t$는 우리가 찾을 관측값이고, 이 관측값과 이전 값들의 에러($a$)에다 계수를 곱해 값을 예측하는 것이다. AR의 경우 관측값 가지고 예측을 하지만, MA의 경우는 분포를 가정하고 가정한 분포에서 샘플링 해 분석을 진행하기에 샘플에 대해서 덜 종속적이게 된다. 일반적으로는 정규 분포를 사용하나, 딥러닝에서는 다른 분포를 사용하기도 한다. 샘플에 덜 종속적이게 되어서 데이터에 불확실성을 가지고 접근하는 것이다. 일종의 생성 모델이라 보면 된다.
이 두 모델을 결합한 모델이 바로 ARMA가 된다. 즉, AR(p)와 MA(q)를 결합한 모델이다. AR 혹은 MA 만을 고려하는 경우보다 일반적으로 성능이 좋다고 한다. ARMA에서 차분까지 결합한 모델이 ARIMA가 된다. 즉 AR(p) + MA(q)를 d만큼 차분한 모델이다. ARIMA(p, d, q)
AR 같은 경우는 PACF를 기반으로, 시차 p 를 설정하고, MA 같은 경우 ACF를 통해 시차 q를 설정한다. p, q는 하이퍼 파라미터로 하나의 가정이며, 실험을 통해 찾아야 된다. 하루를 주기로 두고 하는 연구에서는 도메인 지식으로 볼 때 24시간을 주기로 보는 것이 좋겠지만, ACF나 PACF를 적용하면 다른 p,q가 나올 수 있다. 이때는 연구자의 판단하에 p,q를 설정해야 된다. p 시점 이후에 0 이 되면 그 이후 시점은 연구자가 판단한다는 것이다.
SARIMA(Seasonal ARIMA)
기존의 ARIMA 모델은 추세만을 고려해 정상 시계열로 변환하고 분석을 진행했다. 여기에서 계절 성분을 추가해 나온 것이 SARIMA 모델이다.
\[ \text{ARIMA(p, d, q)} + \text{S(p, d, q)} = \text{SARIMA} \]
계절성이 명확하게 보이는 경우 SARIMA를 사용해서 모델링 한다. 실제 계절성이 존재해 상관관계가 존재한다고 하더라도 이것이 인과관계를 의미하는 것은 아니기 때문에 도메인 지식이 들어가야 한다.
이와 같은 과정을 수행하는 과정은 Box-Jenkins Procedure를 사용한다. 먼저 데이터를 확인하고, 정상 시계열이 아닌 경우 로그나 차분을 통해 데이터를 변환한다. 그 후 모델을 선택하고, 결과를 확인한다. 이때 결과가 제대로 안나온다면 위 과정을 반복하는 방향으로 진행한다. 이러한 과정을 바로 Box-Jenkins Procedure이라고 한다.
ARIMA에 대한 코드는 여기를 참고하면 된다.
Horizon
Horizon은 시계열 모델의 예측값 즉, $\hat{y}$의 예측 범위를 나타낸다. 예측의 경우에는 예측 범위를 의미하고, 이상치 탐지(Anormaly Detection)의 경우 이상치를 탐지할 범위를 의미한다. 만약 예측 범위가 1개인 경우에는 Single-Horizon이라 부르고, 2개 이상인 경우에는 Multi-Horizon이라 부른다.
'Time-Series' 카테고리의 다른 글
| [Time-Series] Time-Series with Machine Learning (0) | 2022.06.01 |
|---|---|
| [Time-Series] 시계열 데이터에서의 교차검증(Cross-Validation) (1) | 2022.05.25 |
| 시계열 데이터에서 전처리하는 방법 (0) | 2022.05.24 |