Contents
LSTM (Long Short-Term Memory)은 RNN (Recurrent Neural Network)가 가지고 있는 장기 의존성 문제(long term dependency)를 해결하기 위해 제안된 모델이다. hidden state $h_t$와 cell state $c_t$로 구성되어 있으며, $h_{t-1}$은 t-1번째 Layer의 hidden state를 의미한다. $h_0$은 초기 hidden state를 의미하며, 0으로 설정한 후 학습을 진행한다.
\[ \begin{equation} \begin{split} i_t & = \sigma(W_{ii} x_t + b_{ii} + W_{hi} h_{t-1} + b_{hi} ) \\ f_t & = \sigma ( W_{if} x_t + b_{if} + W_{hf} h_{t-1} + b_{hf} ) \\ g_t & = \text{tanh} (W_{ig} x_t + b_{ig} + W_{hg} h_{t-1} + b_{hg} ) \\ o_t & = \sigma (W_{io} x_t + b_{io} + W_{ho} h_{t-1} + b_{ho} ) \\ c_t & = f_t \odot c_{t-1} + i_t \odot g_t \\ h_t & = o_t \odot \text{tanh} (c_t) \end{split} \end{equation} \]
$i_t$, $f_t$, $g_t$, $o_t$는 각각 input, forget, cell, output gate를 의미한다. $\odot$은 아다마르 곱(Hadamard product) 혹은 원소별 곱(element-wise product)라고 부른다. LSTM의 state에 대한 수식은 위와 같고 개념적인 부분을 짚고 넘어가고 싶다면 제안한 논문을 살펴보면 된다.
LSTM
parameters
LSTM의 입력으로는 input_size, hidden_size, num_layers, bias, batch_first, dropout, bidirectional, proj_size가 존재한다. 하나하나씩 뜯어서 살펴보자.
input_size
입력으로 주어지는 단어의 feature의 수를 입력하면 된다. 만약 NLP를 예로 들면, 입력으로 사용하기 위해 vocab size 만큼의 look up table을 생성한 후 Latent Vector의 길이를 정해주어야 한다. 즉, embedding size를 지정해주어야 한다. NLP에서는 Look up table을 만들어 단어의 index를 입력하면 One-hot Vector로 변환하여 입력으로 사용한다. 예를 들어, 1000개의 단어가 존재한다고 하면 1000 by 1000 matrix 구조를 만들 수 있을 것인데, 이를 1000 by embedding size 만큼으로 축소하는 것이다.
embedding = nn.Embedding(vocab_size, embedding_size)
# if number of embedding size is 100 / 1000 by 1000 matrix -> 1000 by 100 matrixNLP 분야가 아니라 주가 예측이나 정형 데이터를 사용하는 경우 이와 같은 embedding은 따로 해주지 않아도 된다.
hidden_size
hidden size는 hidden statet $h$의 차원 수를 의미한다. 이는 입력으로 들어온 $x$를 다시 hidden size로 변환하는 것이다. 입력으로 $x \in \mathbb{R}^{m \times n}$가 들어왔다면, $x$에 어떠한 weight matrix $W$를 곱하여 $h \in \mathbb{R}^{m \times h}$ h차원의 matrix로 바꾸어 주는 것이다.
num_layers
num_layers는 재귀 층(Recurrent Layer)의 개수를 의미한다. 기본적인 LSTM 모델에서는 Recurrent Layer가 1개 이지만, Layer를 stacking을 통하여 2개의 Layer를 가진 LSTM을 만들 수 있다. 기본 값은 1이며, 아래의 그림을 보면 조금 더 직관적으로 이해할 수 있을 것이다.

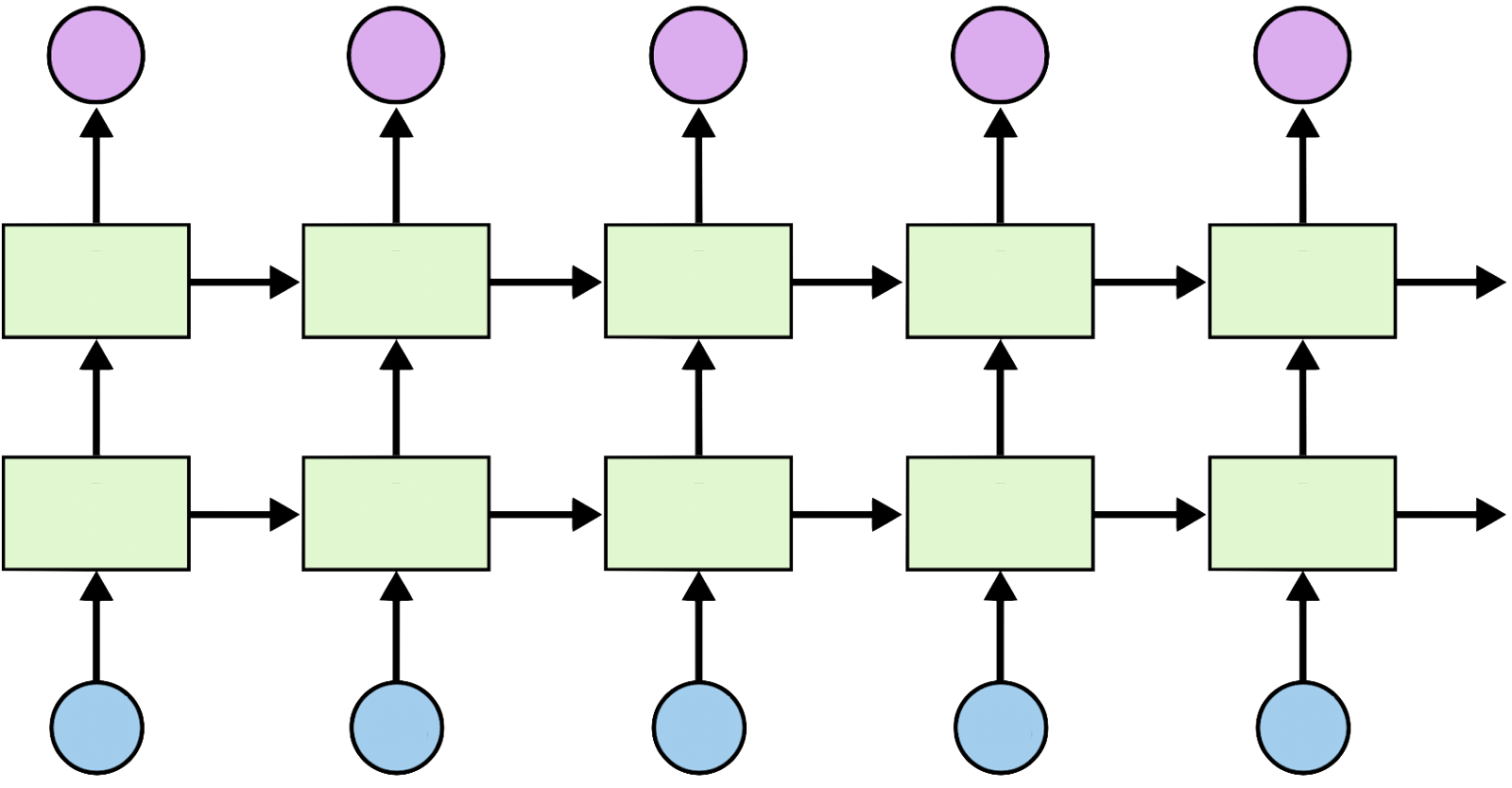
왼쪽 그림의 경우 Layer를 하나만 사용한 LSTM 모델을 의미하고, 오른쪽 그림의 경우 Layer를 2개 쌓은 LSTM 모델을 의미한다.
bias
bias는 편향을 의미한다. 위 수식을 살펴보면 $i_t$, $f_t$, $g_t$, $o_t$ 에 bias $b$가 보일 것이다. 이는 모델에 bias를 주는 것을 의미하며 bias를 주고 싶지 않을 경우 False로 변경해주면 된다. 기본 값은 True로 지정되어 있다.
batch_first
batch_first는 단어에서도 느껴지듯 batch size를 맨 앞으로 설정할 것인가를 다루는 변수다. 만약 모델을 입력할 때 (batch, seq, feature) 형태로 사용하는 경우에는 batch_first=True로 지정하면 된다. 기본 값은 False이며, batch_first=False로 설정한 경우 (seq, batch, feature) 형태로 반환된다.
dropout
모델의 과적합을 방지하기 위해 드롭아웃(Drop-out)을 주로 사용하는데, 만약 dropout이 0이 아니라면, last layer를 제외한 나머지 LSTM layer에 dropout을 적용한다. torch의 test 단계에서는 model.eval()을 설정하게 되는데 이때는 dropout은 자동으로 해제된다.
bidirectional
bidirectional을 bi-LSTM을 사용할 때 True로 지정하면 된다. 기본 값은 False로 지정하면 된다. 기본 LSTM의 경우 output 이전 까지의 hidden state를 가지고 다음을 예측하면 되지만, bidirectional=True로 지정한 경우 이전 hidden state 2개를 호출하여 연결(concatenate)한 후 사용하여야 한다.
# pseudo code
if bidirectional:
output, (hidden_state, cell_state) = lstm(x)
hidden = torch.cat([hidden_state[-1], hidden_state[-2]], dim=-1)
pred = fully_connect_layer(hidden)
else:
output, (hidden_state, cell_state) = lstm(x)
pred = fully_connect_layer(hidden_state[-1])fully_connect_layer는 LSTM을 통과한 후 나온 값을 class 개수만큼의 차원 수로 변환하기 위한 layer라고 생각하면 된다. 예를 들어 감성분석을 하는 경우 긍정(1), 부정(0)의 확률 값을 나오게 하기위한 layer로 이해할 수 있다. (nn.Linear를 사용하고 난 후 nn.Softmax를 취하는 경우!)
Input
LSTM을 입력으로 사용할 때에는 두가지 구조로 사용이 가능하다. many to one 형태로 사용할 때에는 input만 사용하면 되지만, sequence to sequence 모델과 같이 각각의 state마다 값을 출력해야 되는 경우 $h_0, c_0$을 input과 함께 사용함으로써 모델을 구현할 수 있다.
LSTM은 $(L, H_{in})$ 사이즈의 tensor를 입력으로 사용할 때 batch_first=False로 지정한 경우 $(L, N, H_{in})$으로 input sequence의 feature가 구성된다. 만약 batch_first=True로 지정한 경우에는 $(N, L, H_{in})$으로 구성된다. 이때 $N$는 batch size를 의미하고, $L$과 $H_{in}$은 각각 sequence의 길이, input size를 의미한다. 이때 $h_0$과 $c_0$은 각각 hidden state의 초기값과 cell state의 초기값을 의미한다. 기본 값은 0이다.
Output
output도 input과 동일한 구조를 가지고 있다. (output, ($h_n, c_n$)) 형태로 출력이 되며, output은 LSTM의 마지막 layer로 부터 도출된 $h_t$를 의미한다. $h_n$은 각각의 element를 계산하기 위한 hidden state를 의미한다. LSTM 구조는 hidden state를 가지고 다음 단어를 예측하는 형태로 진행하기에 output이 아닌 hidden state를 다음 layer에 입력으로 사용한다. bidirectional LSTM을 사용하는 경우에는 $(2 * \text{num_layers}, H_{out})$으로 나오며, $h[-1]$은 가장 마지막 layer의 last hidden state, $h[-2]$는 그 전 layer의 last hidden state를 의미한다. 만약 layer를 5 층으로 쌓았다면 $h[-5]$까지의 hidden state를 연결(concatenate)해서 다음 입력으로 사용하여야 한다.
Implementation
먼저 LSTM 구축에 필요한 패키지를 불러오자.
import typing
import torch
import torch.nntyping은 입력 데이터의 자료형 구조를 보여주기 위해 사용하는 패키지라 따로 호출하지 않아도 상관없다. LSTM을 구축하기 위해서는 torch 기본 구조만 있으면 충분히 구현이 가능하다.
class lstm(nn.Module):
def __init__(self,
vocab_size : int,
embedding_size : int,
hidden_size : int,
output_size : int,
n_layers : int,
bidirectional : bool,
dropout_rate : float,
pad_index : int
) -> None:
super(lstm, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size, padding_index = pad_index)
self.LSTM = nn.LSTM(
input_size = embedding_size,
hidden_size = hidden_size,
num_layers = n_layers,
bias = True,
batch_first = True,
dropout = dropout_rate,
bidirectional = bidirectional
)
self.fully_connect_layer = nn.Linear(2 * n_layers if bidirectional else n_layers, output_size)
self.dropout = nn.Dropout(dropout_rate)처음 초기치 설정(initialization)하는 단계이다. 위에서 언급한 parameter들을 볼 수 있다. 만약 NLP 가 아니고 주식 예측 등과 같은 정형 데이터를 입력으로 사용하는 경우 vocab_size가 아니라 input_size로 변경해도 무방하고, 이때는 self.embedding을 지우고 사용하면 된다. NLP에서는 입력 문장의 길이가 각각 다르기 때문에 padding을 수행한다. 이때 padding token은 [PAD] 혹은 <pad>로 지정하는데, 해당 index를 embedding에 지정해주어야 모델이 이를 학습하지 않는다.
def forward(self, ids, length):
embedded = self.embedding(ids)
if self.dropout:
embedded = self.dropout(embedded)
embedded = nn.utils.rnn.pack_padded_sequence(embedd, length, batch_first=True, enforce_sorted=False)
output, (hidden_state, cell_state) = self.LSTM(embedded)
output, output_length = nn.utils.rnn.pad_packed_sequence(output)
if self.LSTM.bidirectional:
hidden_state = self.dropout(torch.cat([hidden_state[-1], hidden_state[-2]], dim=-1)
else:
hidden_state = self.dropout(hidden_state[-1])
pred = self.fc(hidden_state)
return pred
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LSTM):
for name, param in m.named_parameters():
if 'bias' in name:
nn.init.zeros_(param)
elif 'weight' in name:
nn.init.orthononal_(param)배치 단위로 모델을 학습하지 않는 경우에는 pack_padded_sequence를 따로 사용하지 않아도 된다. 그러나 배치 단위로 모델을 학습하는 경우에는 pack_padded_sequence의 중요성이 대두된다. NLP에서는 매 배치마다 고정된 문장의 길이로 만들어주기 위해 <pad> token을 사용하여야 한다. 배치 단위로 문장이 들어오기 때문에 문장 마다 길이가 다를 수 있다. 배치의 첫 번째에 위치한 문장과 마지막에 위치한 문장의 경우 단어의 수가 10개로 구성되어 있고 두 번째부터 아홉 번째까지의 문장은 단어가 2개로 구성되어 있을 수 있다. 이때 pack_padded_sequence를 따로 수행하지 않고 작업을 할 경우 배치 단위로 학습하기 때문에 두 번째부터 아홉 번째까지의 문장은 세 번째 단어부터 연산을 할 필요가 없음에도 불구하고 연산을 수행하게 된다.
pack_padded_sequence는 배치에 구성된 문장의 길이를 기준으로 정렬하여 불필요한 연산을 하지 않게 구성하여 속도를 개선시키는 방법이다. 아래의 그림을 확인하면 보다 직관적으로 이해할 수 있다.
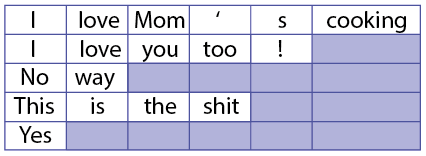
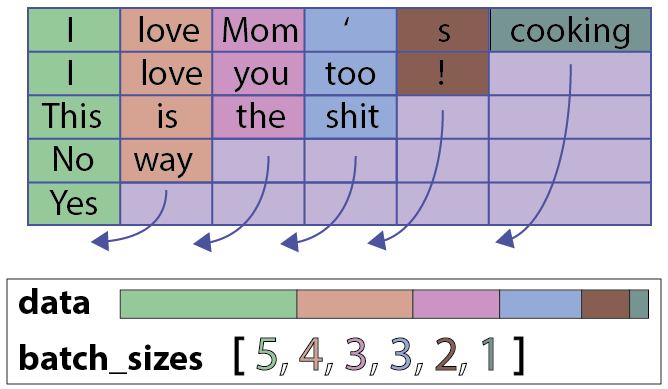
전체 코드를 확인하고 싶으시면 여기에 방문해 주세요.
[1] https://simonjisu.github.io/nlp/2018/07/05/packedsequence.html
[2] https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html
'Python > Pytorch' 카테고리의 다른 글
| [Error] CUDA-LAUNCH_BLOCKING=1 error (0) | 2022.06.25 |
|---|---|
| [Error] module 'scipy.sparse' has no attribute 'coo_array' (0) | 2022.06.23 |
| [Error] Broken pipe (0) | 2022.06.23 |
| [Pytorch] Pytorch 에서 모델 요약 보기 with torchsummary (0) | 2022.04.18 |
| [Pytorch] CUDA error: device-side assert triggered (0) | 2022.04.13 |