Contents
LangGraph Introduction
LLM을 사용하다 보면 LangChain과 LangGraph에 대해서 들어보았을 것이다. 두 패키지는 LLM을 쉽게 사용할 수 있고, LLM이 가지고 있는 환각(Hallucination)을 완화하기 위해 제안되었다. LLM의 가장 고질적인 문제인 환각 현상을 회피하기 위해 RAG(Retrieval-Augmented Generation)이 제안되었고, RAG는 LLM에서 학습되지 않은 정보에 대해서 답변할 때 인터넷 혹은 논문 등과 같은 정보를 활용하여 환각이 발생하지 않고 정확한 답변을 내는 기법 중 하나라고 볼 수 있다.
금융권이나 업무 보조 등으로 LLM을 사용하는 경우에는 관련 약관을 제공하거나 법률 등의 질문에 대한 답변에서 환각이 발생하게 되면 큰 문제로 이어지기 때문에 속도가 느리더라도 정확도가 매우 중요하다. 이런 경우에는 실제 내부의 보험 약관 자체를 RAG로 구성하여 검색을 통해 정확한 답변을 생성하게 된다.
이번 글에서는 LangGraph에 대해서만 다루고, RAG와 Lanchain의 디테일한 정보는 다른 글에서 다룰 예정이다. LangGraph가 무엇인지, 어떻게 사용하는지에 대해서 알아보자.
LangGraph는 기본적으로 Node와 Edge로 구성되어 있기 때문에 Graph로 표현한다. 이때 Node는 각 세부 과정들을 의미하고, Edge는 Node와 Node를 연결하는 간선으로 볼 수 있다. 이때 조건부 Edge를 사용할 수 있는데, 조건부 Edge는 특정 조건에 만족하는 경우에 다음 Node를 실행하는 로직이라고 보면 된다.
일반적인 Q&A 과정은 질문(Question) - 검색(Retrieve) - 답변 생성(Generation) - 답변(Answer) 형태로 구성된다. 이때 질문, 검색, 생성, 답변을 Node로 생각하면 되고, 둘을 순서대로 이어주는 '-'을 Edge라고 이해하면 된다. 위 과정에서 웹 검색 (Web Search) 라는 Node를 추가하고 나서 질문 후 검색을 수행하고, 웹 검색을 통해 서로 검증 후 답변하는 조건문 Edge를 생성할 수 있다.
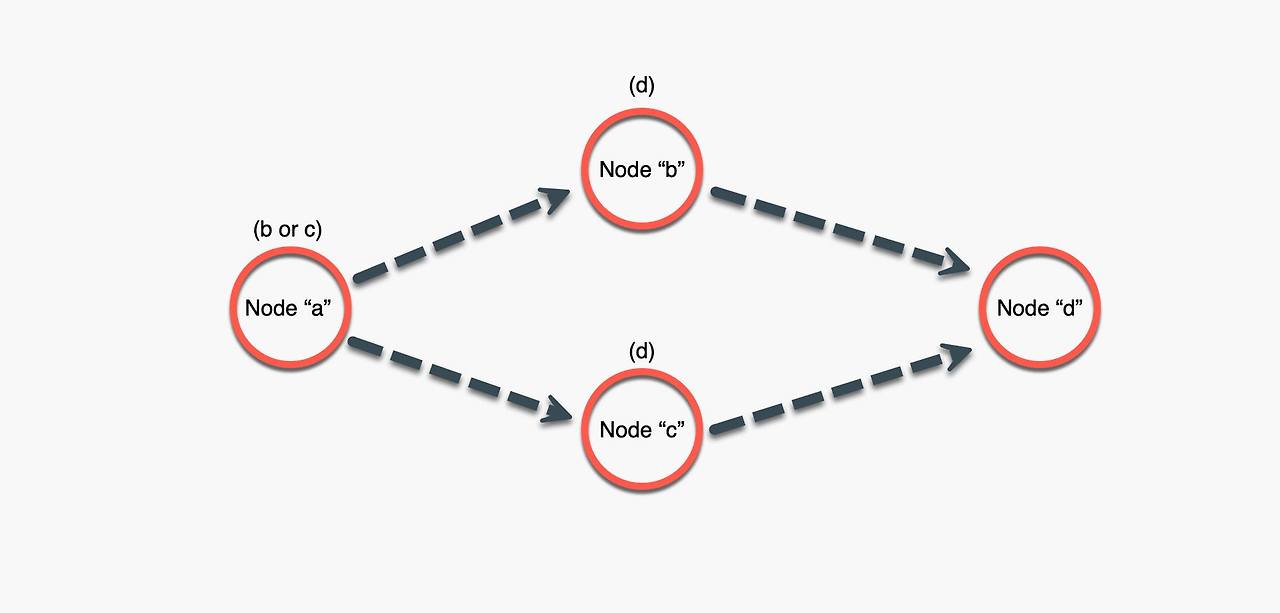
Node를 서로 연결하기만 한다면, 관계만 파악하기 때문에 작동이 되지 않을 것이다. 그래서 State를 따로 사용하여 Node에서 다음 Node로 Edge를 활용하여 State를 전달해 조건부 Edge의 종료/진행 여부를 정할 수도 있고, CheckPoint 등을 만들 수도 있다. 개략적인 LangGraph에 대한 내용은 알아봤으니 코드로 더 자세히 알아보자.
Implementation
Graph State 정의
LangGraph에서는 기본적으로 typing을 명시하여 사용하고 있다. 실제 입력으로 들어오는 값이 int인지 str인지, list인지를 명확하게 구분하여 어떤 데이터 유형이 들어오더라도 해당 type으로 변환하여 사용하기 위함이다.
from typing import Annotated, TypedDict, List, Dict
from langchain_core.documents import Document
from langgraph.graph.message import add_messages
# import operator
class State(TypedDict):
messages: Annotated[list, add_messages] # operator.add
State는 Node에서 다음 Node로 제공해주는 GraphState를 의미하고, 해당 정보에는 답변 뿐만 아니라, 질문, 검색 결과, 관련성(Relevance) 등을 전달할 수 있다. add_message는 과거에 전달 받았던 Message를 list에 계속 append한다는 것을 의미한다. 만약에 단순히 Annotated[str, "Answer"]으로 표현한다면 과거에 받은 정보는 없어지고 계속 Update되는 형태가 된다. 과거에 나누었던 대화 정보들을 계속 기록하도록 LLM을 구성하려면 add_message를 사용하여야 한다. (add_message 대신 operator.add 사용 가능)
Node 정의
Node는 본인이 정의하기 나름이며, Node는 입력으로 State를 받고 출력으로 State를 반환하면 된다.
from langgraph.graph import StateGraph
def retrieve(state: State) -> State:
documents = 'answer'
return State(context=documents)
def claude_execute(state: State) -> State:
answer = 'answer'
return State(answer=answer)
def relevance_check(state: State) -> State:
binary_score = 'binary_score'
return State(binary_score=binary_score)
def sum_up(state: State) -> State:
answer = 'sum'
return State(answer=answer)
workflow = StateGraph(State)
workflow.add_node('retrieve', retrieve)
workflow.add_node('question', claude_execute)
workflow.add_node('relevance', relevance_check)
workflow.add_node('results', sum_up)
지금 구조는 질문 - 답변 - 정리 과정으로 보면 된다. 각각의 Node에 해당하는 정보를 작성하고 우리가 원하는 흐름의 Edge를 연결하면 기본적인 세팅은 완료된다. StateGraph는 LangGraph 내에 존재한다.
Edge 정의
from langgraph.graph import END
workflow.add_edge('retrieve', 'question')
workflow.add_edge('question', 'relevance')
workflow.add_edge('relevance', 'results')
workflow.add_edge('results', END)
조건부 Edge가 아닌 일반적인 Edge의 경우에는 단순히 이렇게 연결만 하면 된다. 중요한 부분은 LangGraph의 마지막 지점을 END로 지정해서 실제 workflow의 마지막을 지정해주어야 한다.
Conditional Edge 정의
def decision(state: State) -> State:
decision = 'decision'
return decision
workflow.add_conditional_edges(
'summary',
decision,
{
're-retrieve': 'retrieve',
'end': END
}
)
# workflow.add_edge('results', END) 주석필요
Conditional Edge를 설정하기 위해서는 add_edge가 아닌 add_conditional_edge로 쉽게 활용이 가능하다. 먼저, 조건에 따라 결정을 내릴 수 있는 Node를 추가로 하나 더 설정하여야 하고, 그 결과에 따라서 if인 경우에는 재검색(re-retrieve)을 수행하고 아닌 경우에는 END로 종결하는 형태의 논리 구조를 짤 수 있다.
langgraph.graph 내의 START로 시작지점을 지정해주어도 되고, 하기 코드를 통해 시작 State가 어딘지 지정해주어도 된다. 그리고 memory를 할당하여 graph를 compile하면 llm의 논리 구조를 전부 만들었다.
from IPython.display import Image, display
workflow.set_entry_point('retrieve')
memory = MemorySaver()
from langgraph.checkpoint.memory import MemorySaver
graph = workflow.compile(checkpointer=memory)
# visualization
display(Image(graph.get_graph().draw_mermaid_png()))

최종 graph를 시각화하게 된다면, Retrieve - Question - Results 형태로 나오는 것을 확인할 수 있고, set_entry_point를 통해 시작지점을 설정하고 END를 통해 끝지점을 설정했기 때문에 __start__, __end__도 함께 출력되는 것을 확인할 수 있다. 조건부 Edge를 넣은 것과 넣지 않은 것과는 Loop가 생기냐 생기지 않냐 정도로 볼 수 있다.
재검색 과정이 없는 경우에는 LLM이 잘못된 답변을 하더라도 사용자는 무조건 그 정보를 제공받아야 한다. 만약에 if else로 구성된 추가의 조건부 Edge를 설정하여 재검색 과정을 추가하면 LLM이 첫 번째로 잘못된 답변을 수행하더라도 한 번 다시 생각하고 수정할 수 있어서 보다 정확한 정보를 제공받을 수 있다.