PCA(Principal Components Analysis) 란?
대표적인 차원 축소(dimension reduce) 방법 중 하나다. 본인이 가진 데이터를 최대한 보존하면서 compact 한 자료를 만드는 것이 목적이다. 전진 선택법, 후진제거법, 유전 알고리즘 등 변수제거를 하는 방식이 아니라 차원을 축소하는 것이다. 원래 데이터의 분산을 최대한 보존할 수 있는 기저를 찾는 것이다. 각 점 $x^{(i)} \in \mathbb{R}^n$에 대해 그에 대응되는 code vector $c^{(i)} \in \mathbb{R}^l$을 구한다음 만약 $ n \ge l$이라면 원래보다 더 적은 메모리로 code point에 저장할 수 있을 것이다.

$ Var(x)_{x\in\mathbb{R^3}} = max(Var(x^\prime)) , x^\prime \in \mathbb{R^{d}}_( d < 3 )$
예를 들어 아래와 같이 7이라는 이미지가 있으면 7로 분류하려고 하는데, 7의 차원이 28*28으로 784 차원으로 되어 있다면 여태껏 어느 변수들과는 다른 엄청 큰 feature를 가진 데이터 타입이 되게 됩니다. 그렇기 때문에 PCA로 차원을 2차원 혹은 3차원으로 축소시켜 확인하는 것이다.

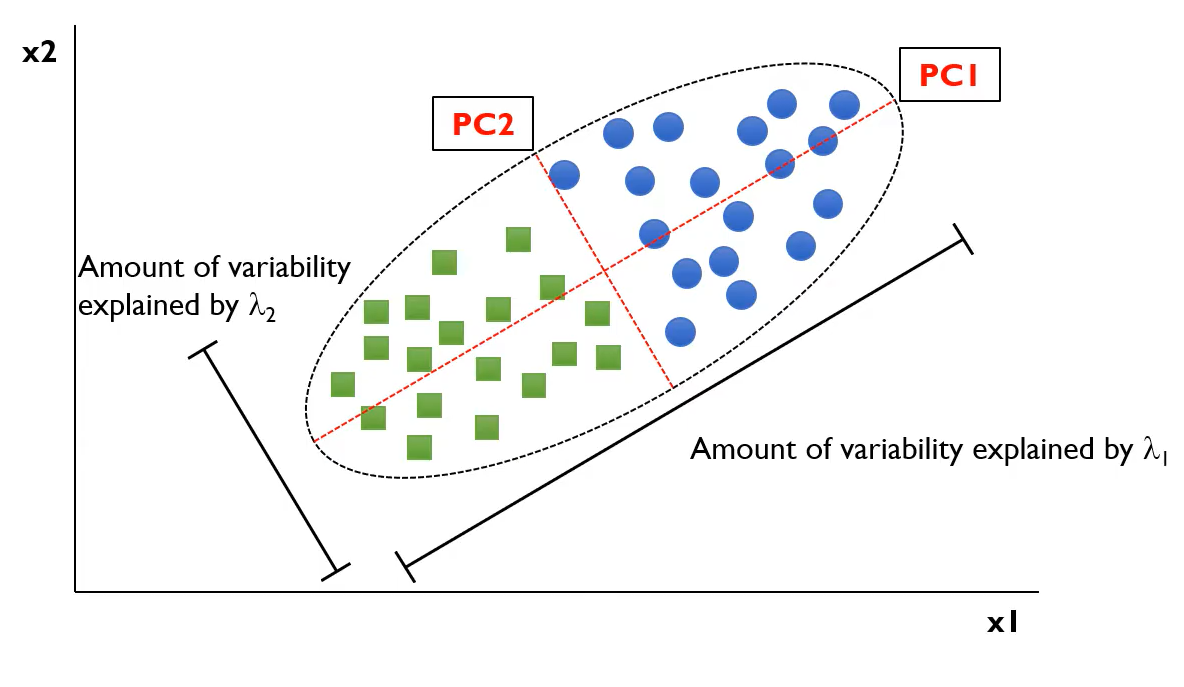
데이터의 분산이 더 큰 기저를 선호하겠다라는 뜻이며, 그 기저의 역할은 분산을 가장 많이 보존하는 것이다. 원래의 변수를 X로 표현하고, principal component 를 a라고 하겠다. 이렇게 나온 분산 값을 계산하여 이 분산이 최대가 되는 기저a를 찾아가는 것이다.

첫 번째 기저(basis) 에서 구할 수 있는 분산의 양($\lambda_{1}$)을 찾을 수 있고, 두 번째 기저(basis)에서 구할 수 있는 분산의 양($\lambda_{2}$)을 찾을 수 있다.
Covariance
Covariance는 PCA를 설명할 때 가장 기본적으로 알고 있어야 되는 개념이라고 할 수 있다.
- X = data set ( m by n, m : # of variables, n : # of records ) column vector (m*n = dimension)
- $ Cov(X)_{m*m} = {1 \over n} (X - \bar{X})_{m*n}(X - \bar{X})^{T}_{n*m} $
- $ Cov(X)_{ij} = Cov(X)_{ji} $
- Total variance of the data set : $ tr[Cov(X)] = Cov(X)_{11} + Cov(X)_{22} + ... + Cov(X)_{dd} $
Projection onto a basis

$ \vec{b} $를 정사영 시킨 값 즉, $ \vec{a} $와 수직인 값을 $\vec{b} - p\vec{a} $ 라고 할 수 있다.
$ If \vec{a}$ is unit vector =$ \vec{a}^{T}\vec{a} = 1 $ 1인 값이 나오게 되고, $ p = \vec{b}^{T}\vec{a} $값이 도출된다. $ ( \vec{b}^{T}가\ 나중에\ X가\ 될\ 것이고, \vec{a}가\ w값이\ 될\ 것이다) $
eigen value and eigen vector
하나의 행렬이 주어졌을 때 이 행렬은 $ scalar\ value \ \lambda$와 $ vector\ x $를 갖게 된다. 여기서 방향이 바뀌지 않는 vector를 $x$라고 부르고(eigen vector) 방향이 바뀌고 값이 바뀌는데 그 바뀌는 값을 $ \lambda $라고 한다.


A matrix는 역행렬이 존재하는 d by d 행렬이라고 가정하면, A matrix는 d개의 eigenvalue-eigenvector pairs를 가진다. 모든 eigenvector는 서로 직교한다. $ e_{i}^{T}e_{j} = 0 $
$ tr(A) = \lambda_{1} + \lambda_{2} + ... + \lambda_{d} $
A matrix의 diagonal 합 = $ \sum_{i=1}^d \lambda_{i} $
해당 부분을 개념적으로 접근하고 싶다면 여기를 참고하고, 역행렬에 대해서 조금더 자세히 알고 싶다면 여기를 참고하자
step 1 평균을 0으로
$ Cov(X) = {1 \over n}(X-\bar{X})(X-\bar{X})^{T} $
평균을 0으로 만들어주게 되면 $ \bar{X} $ 값이 0이 되어서 $XX^{T}$ 형태로 된다. 원점을 데이터 셋을 중심으로 옮겨주기 위함이다
from sklearn.preprocessing import StandardScaler
sds = StandardScaler()
x[iris.feature_names] = sds.fit_transform(x[iris.feature_names])
step 2 최적화
$ V= {1 \over n}(w^{T}X)(w^{T}X)^{T}\ = {1 \over n}w^{T}XX^{T}w = w^{T}Sw $
$X$는 normalization 된 X값이다.
$S$는 X의 normalization한 것에 covariance 를 구한 것이다.
$ max(w^{T}Sw) \ s.t.w^{T}w=1 $
$ L = w^{T}Sw - \lambda(w^{T}w -1) $
$ {\partial L \over \partial w} = 0 \Rightarrow Sw - \lambda w = 0 \Rightarrow (S-\lambda\mathbf{I})w = 0 $

step 3 기저 찾기
$ V= (w_{1}^{T}X)(w_{1}^{T}X)^{T}\ = w_{1}^{T}XX^{T}w_{1} = w_{1}^{T}Sw_{1} $
$ Since\ Sw_{1} =\ \lambda_{1} w_{1},\ w_{1}^{T}Sw_{1} = \lambda_{1} $
$if \ {\lambda_{1} \over \sum_{i=1}^d {\lambda_{i}}} = 0.67 $ : $\lambda_{1}$가 67% 의 설명력을 지님.
주성분을 두가지 선택했을 경우 97%의 설명력을 지닐 수 있다


단점
1. 몇개의 주성분을 사용하여 차원을 축소할 것인가에 대한 명시적인 정답은 없다.
2. 정량적, 정성적인 방법으로 판단할 수 있다. (몇 퍼센트의 값을 가져올 것인가?, 전문가의 견해가 담긴 차원 축소)
- 정량적인 판단에서는 elbow point 를 선택하는 경우가 대부분, 평가기준이 사람마다 다르다.
3. 비선형적인 구조를 가진 데이터에서는 좋은 설명력을 가질 수 없다.
