다음의 사진은 Semantic Segmentation을 하는 과정을 설명한다. 우리는 이미지에서 각 pixel마다 그 pixel이 어떤 것인지 분류를 하는 문제다. 우리는 이전에 AlexNet, GoogLeNet, ResNet 등 여러 CNN model을 공부해왔다. 만약 개, 고양이를 분류하는 문제를 다룬다고 할 때 이미지의 라벨이 개인지 고양인지 분류하는 문제로 접근하는 것이 아니라, 해당 pixcel은 배경이고, 사람이고, 물체임을 분류하는 방식의 접근이 Semantic Segmentation이다. Semantic Segmentation은 여러 용어로 불리우는데 Dense Classificaiton 혹은 per pixel classification이라고 한다.

딱봐도 일반적인 이미지를 분류하는 문제와는 다르고, 상당히 어려워보인다. 그렇다면 Semantic Segmentation은 어디서 사용될까? 아래의 그림을 보면 사람과 동물, 나무, 차량 등 분류가 되어있는 것을 확인할 수 있다. Segmantic Segmentation은 주로 자율주행 문제에 활용이 된다. 자동차에 카메라가 있을 때 카메라는 자동차의 바로 앞에 있는 것이 사람인지, 인도인지, 차도인지 등 분류를 할 수 있어야 한다. 만약 앞에 있는 이미지가 사람이라면 멈춰야하고, 그럼 자율적인 문제를 수행할 수 있기 때문이다.

기존의 CNN의 분류 문제를 생각해보면 conv layer를 거쳐 BN, nonLinear activation function 등을 거쳐 fully connected layer(Dense Layer)를 통과해 마지막 원하는 class 만큼 output을 출력하는 형식으로 진행되었다. Semantic Segmentation의 기본이 되는 아이디어는 다음과 같다.
원래 fully convolutional 의 자리에는 nn.Linear(x.size(0), -1) 의 형태로 펼쳐서 fully connected layer를 만들어주는 것인데 기존의 Dense Layer(fully connected layer)를 없애고 Fully convolutional network로 만들어주는 것이다. Dense Layer를 없애주는 과정을 convolutionalization이라고 부르고, 이것의 가장 큰 장점은 Dense Layer가 없어지는 것이다.
원래는 flat과정을 거쳐 output을 출력하는 방법이나 Dense Layer를 convolutionalization해서 output을 출력하는 방법은 둘다 똑같은 output을 출력하고 동일한 parameter수를 가진다. 만약 그 전 layer의 size가 1000x20x20 을 가졌다면 Flat하게 만들어 Dense Layer(40만개)를 만들어주느냐, 1000x20x20 kernel을 통해 1x1x1000 짜리 featur map을 만드는 것이다.


4x4의 H,W를 가지고 16개의 채널로 구성된 feature Map이 있으면 flat하게 만든 fully connected layer는 4x4x16으로, 10개의 output을 출력한다면 parameter수는 2560개가 된다. 오른쪽의 경우를 보면 4x4x16의 feature Map을 4x4 filter로 convolution하게 되면 4x4x16개의 filter가 생성되고 똑같이 4x4x16x10 =2560개가 된다. filter의 채널은 이전 feature Map의 채널이 동일하다.

그렇다면 왜 기존의 Dense Layer를 사용하지 않고, Convolutionalization을 하는 것일까? 첫 번째로 Fully Convolutional Network가 가지는 특징은 input의 dimension에 independent하다는 것이다. 이 convolutional Network는 input image에 대해서 filter를 거쳐서 넘어오기 때문에 Dense Layer와는 달리 convolution layer가 가지는 shared parameter의 성질 때문에 그 이미지의 pixel에 대한 spacial dimension 정보가 남아있다. 그렇기 때문에 convolution으로 변형하면 해당 feature map은 heat map과 같은 출력을 만들어낸다.
Fully Convolutional Network(FCN)는 어떠한 사이즈의 inputs(FCN의 input은 spacial dimension을 말한다.)이 들어와도 돌아갈 수는 있지만 처음 모델에 들어오는 input size와 FCN에 들어오는 input간의 차이가 크다면 spacial한 정보가 많이 없기 때문에 좋은 결과가 나타나지는 않는다. FCN을 통과한 후 이미지의 정보를 원래의 이미지로 복원할 때 여러가지 방법론들이 등장한다.

Deconvolution ( conv transpose )
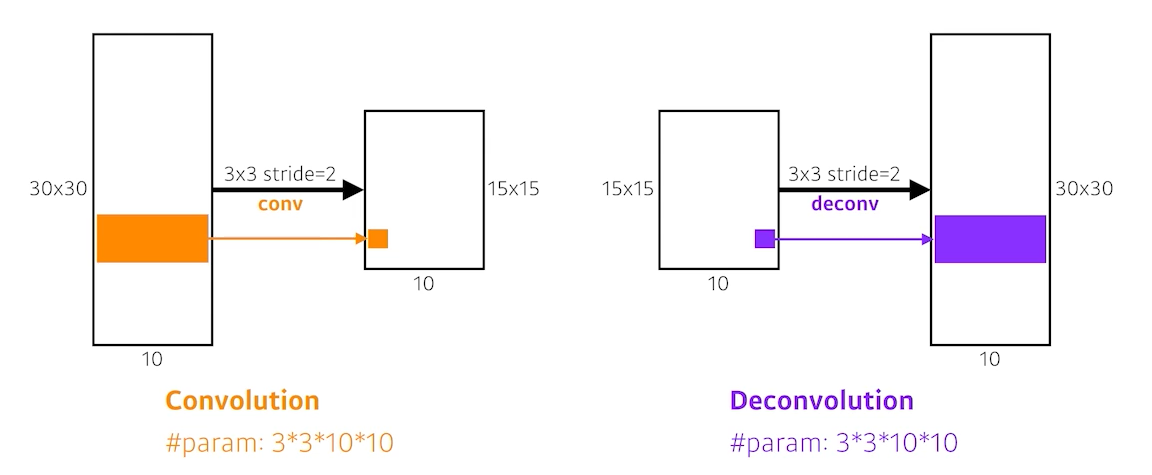
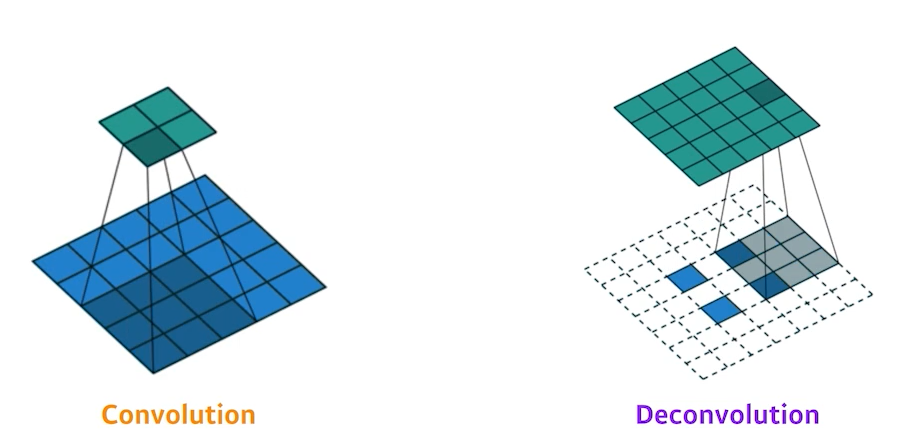
Deconvolution은 직관적으로 바라볼 때 De + convolution 즉, convolution을 역으로 연산하는 것이다. 우리가 convolution 연산을 수행할 때 stride=2를 주게 되면 대략 반 정도 줄어들게 된다. ($ \frac{size - filter + 2*padding}{stride} + 1$ 이기 때문에) 아래의 경우에 Deconvolution을 하게 되면 15x15의 이미지가 30x30으로 두 배 증가한다.
엄밀하게 들어가면 우리는 3x3 convolution 연산을 할 때 3x3 의 정보가 하나의 pixel로 출력되기 때문에 다시 역으로 연산하는 과정에 있어서 원래 pixel로 복원하는 것은 불가능하다. Deconvolution 도 엄밀히 말하면 convolution 연산의 역은 아니다. 아래의 경우를 예로 들면 Deconvolution은 각 값에 padding을 크게 줘서 결과론적으로 보면 Deconvolution을 통해 5x5이미지를 만들 수 있도록 조작하는 방법이다.
'Deep Learning > Computer Vision' 카테고리의 다른 글
| Convolutional Neural Network (CNN) 밑바닥부터 구현하기 (0) | 2022.11.17 |
|---|---|
| [VISION] Convolution Neural Network (0) | 2021.10.20 |
| [Regularization] variety methods of Regularization (0) | 2021.10.19 |