BERT는 Bidirectional Encoder Representations from Transformers의 약자이며, 이름에서부터 BERT는 Transformers의 Bidirectional Encoder임을 알 수 있다. Bidirectional은 양방향을 의미하고 Encoder는 입력값을 숫자 형태로 바꾸는 모듈을 의미하기 때문에 BERT는 문맥을 양방향으로 이해해서 숫자의 형태로 바꿔주는 딥러닝 모델이다라고 할 수 있다.
Transformer는 2017년에 구글에서 발표한 Encoder, Decoder구조를 가진 딥러닝 모델이며 Machine Translation(MT)에서 우수한 성능을 보여준 모델이다. BERT에서 Encoder는 양방향으로 처리하고 Decoder는 왼쪽에서 오른쪽으로 단방향으로 처리한다는 큰 차이점을 가졌다. BERT는 왜 Encoder를 양방향의 구조로 가지게 되었을까? 바로 GPT-1 때문이다.
GPT-1
GPT-1은 2018년에 OpenAI에서 Transformer의 Decoder 구조를 가져와 만든 자연어 처리 모델이다. GPT-1은 Generative training으로 학습된 Language Model이 얼마나 자연어처리 능력이 우수한지 보여주는 모델이다. 기본적으로 문장을 데이터로 사용하며 단어를 하나씩 읽어가며 다음단어를 예측하는 방식으로 진행된다. 이와 같은 학습방식은 별도의 labeling 작업이 필요없어 비지도 학습이라고도 할 수 있다. 문장을 가져와 단어를 하나씩 읽어가며 예측하기 때문에 하나의 문장을 가지고 있더라도 여러 Train Data set을 만드는 것이 가능하다. 앞 Train Data를 가져와 GPT-1를 통해 다음 단어를 예측하기 때문에 사람이 따로 Labeling할 필요가 없다. 따라서 GPT-1을 학습하기 위해서는 엄청난 양의 데이터와 그 데이터의 질 또한 좋아야한다.
BERT는 2018년 GPT-1의 발표 이후 얼마 지나지 않아 구글에서 발표한다. 구글은 GPT-1이 단순히 Transformer의 Decoder부분을 가져와 단어를 왼쪽에서 오른쪽 방향으로 학습시키는 과정은 결과가 그다지 좋지 않다라고 하며, 문장을 이해하기 위해서는 한 방향이 아닌 Transformer의 인코더부분 즉 Bidirectional 을 통해 학습을 해야한다고 말하며 BERT라는 이름으로 논문을 발표했다.
Transformer
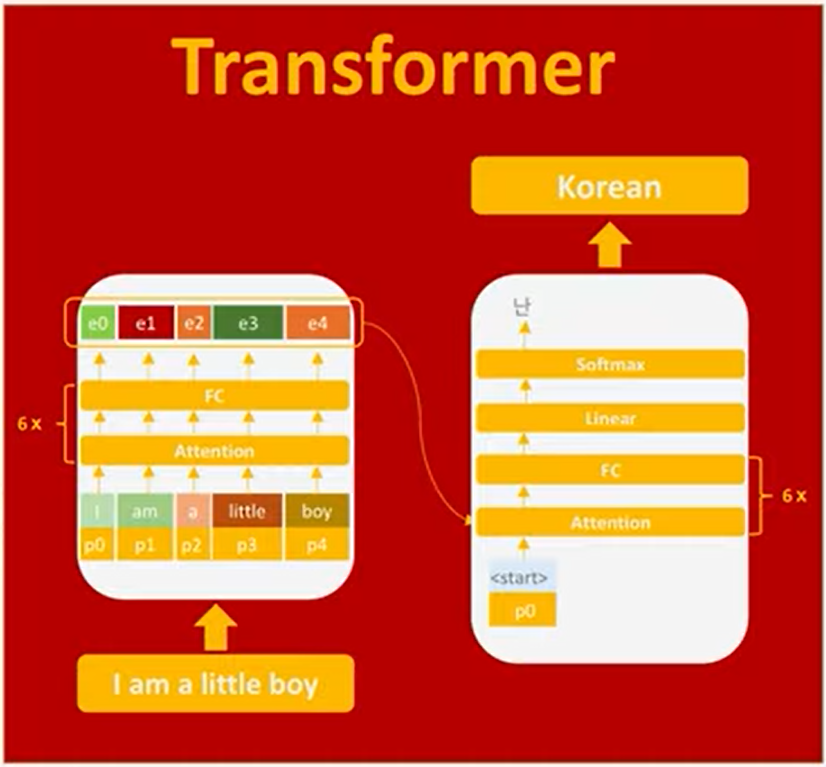
Transformer의 input 값이 각 Encoder에 입력이 되면, token들은 각 positional encoding과 더해지게 되고, encoder는 이 값들을 행렬 계산을 통해 한번에 Attention vector를 생성한다. ( Attention은 RNN의 Bottleneck problem을 해결하기 위해 나온 방법론이다 ) Attention vector는 Fully connected Layer로 전송되는데 이 과정이 총 6번 진행된다. 그 후 출력되는 값은 Transformer의 Decoder의 input값으로 사용된다. Encoder에서는 모든 token을 한번에 계산한다는 점, Decoder와 달리 왼쪽에서 오른쪽으로 읽어나가는 과정이 없다는 점을 꼭 알아야한다. [여기서 transformer를 조금 더 자세히 다룬다. ]
Decoder는 Encoder의 output값을 input으로 받고, 최초 <start> special token으로 작업을 시작한다. Decoder는 계속 말했다시피 왼쪽에서 오른쪽으로 출력값을 생성한다. Decoder역시 Attention vector를 만들고 Fully connected Layer로 보내는 작업을 6번 반복하게 된다. Decoder는 <End> token이라는 만들어낼때까지 반복을 하게 된다.
Tranditional LM vs bidirectional LM (BERT)
기존의 Tranditional LM은 한방향으로 왼쪽에서 시작해 오른쪽의 단어를 학습하는 형태로 진행되어졌다. 하지만 BERT 구조에서는 Bidirectional LM의 형태로 양방향으로 예측할 단어를 masking처리한 후 예측을 하게 된다. 이렇게 masking된 token을 mask token이라 부른다. BERT도 GPT와 같이 사람이 직접 labeling할 필요가 없다. 단순히 random하게 단어를 masking하고 가려진 단어를 맞추도록 학습하는 구조다.
BERT
BERT의 입력값으로는 한문장 뿐만 아니라 두문장도 받을 수 있다. 한문장을 받아 처리하는 LM에는 스팸인지 아닌지 분류하는 모델이 있고, 두문장을 입력받아 학습하는 LM에는 질의 및 응답이 있다. BERT는 한문장 또는 두문장을 입력으로 받아 token간의 correlation 뿐만 아니라 문장 간의 correlation 또한 학습하게 된다. [CLS] token은 분류 task에 사용하기 위한 vector이며, 문장 전체가 하나의 vector로 표현된 special token으로 이해할 수 있다. 아래와 같이 두문장이 입력값으로 된 구조에서는 [SEP]라는 special token이 존재한다.
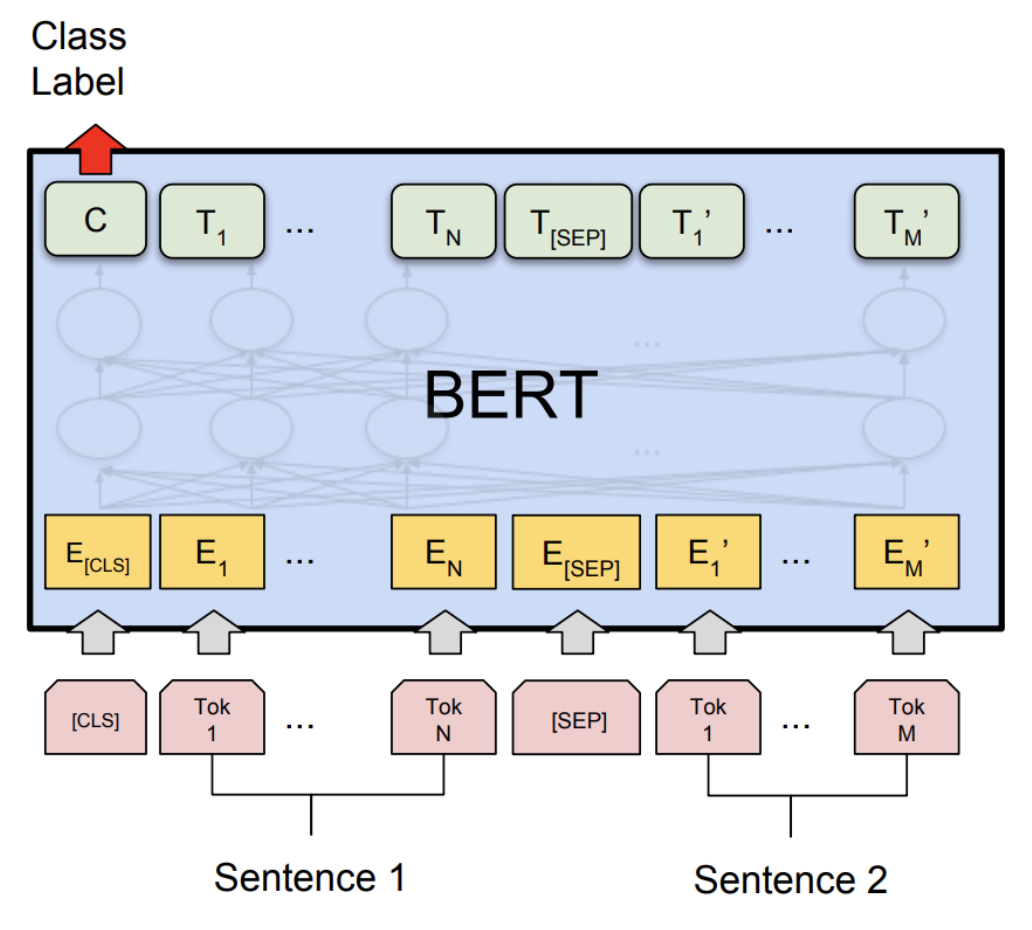
BERT의 Token Embedding과정에서 Token을 WordPiece 형태로 단어를 parsing하게 되는데 WordPiece 형태로 parsing하는 것이 띄어쓰기 기준으로 parsing하는 것보다 더 좋은 성능을 가진다. 예를 들어 Texting 이라는 단어를 생각해보자 Texting은 Text + -ing 두 단어로 쪼갤 수 있으며, 각각의 의미를 전달하는데 더 좋은 효과를 불러온다. 이렇게 단어를 짤라 학습시킴으로써 신조어 등을 학습하는데에 더 좋은 결과를 일으킬 수 있을 것이다.
Segment Embedding과정에서는 두개의 문장이 입력될 경우 각각의 문장에 서로다른 숫자들을 더해주는 것을 한다. 딥러닝 모델에 서로다른 문장이 있다는 것을 쉽게 알려주기 위해 사용된다.
Position Embedding은 Token들의 상대적인 위치 정보를 알려준다. Position Embedding은 Sin, Cos 함수를 사용하게 되는데, 세 가지 이유가 있다고 한다. 첫번째 이유는 Sin과 Cos의 함수는 입력값에 따라 달라지게 되는데, 따라서 입력값의 상대적인 위치를 알 수 있는 숫자로 사용이 가능하다. 두번째이유는 Sin과 Cos의 함수의 출력값은 각 위치에 따라 증가하거나 감소하는 패턴을 가진다. 딥러닝 모델이 이러한 규칙을 사용해 입력값의 상대적인 위치를 쉽게 예측이 가능하다. 마지막으로는 Sin과 Cos 함수는 길이에 대해 제한적이지 않기 때문에 주로 사용된다고 한다.
그럼 BERT에서는 왜 절대적인 위치가 아니라 상대적인 위치를 사용하는 것일까? 만약 절대적인 위치값(1을 더하고 다음 단어에는 2를 더하는 형태)을 사용하게 되면 처음 설정한 위치값보다 큰 단어가 들어오게 된다면 사용을 할 수 없게 된다. 그렇기 때문에 길이가 무한한 단어에도 사용할 수 있는 상대적인 위치에 대해 더 선호하는 것이다.

Fine tuning
BERT는 Fine Tuning을 하기 위해 만들어졌고, GPT는 Fine Tuning을 할 필요가 없도록 만들었다. GPT는 Pre-training 된 모델로 모든 Task를 예측할 수 있지만, BERT는 Task에 맞게 Fine Tuning을 해주어야 한다. 만약 해당 Task가 아닌 다른 Task로 모델을 학습시키게 된다면 모델의 성능은 아작나버린다.. 그렇기 때문에 GPT의 학습량은 BERT에 비해서 엄청나게 크고, 학습하는 과정에 비용이 많이 발생한다. 하지만 BERT는 pre-training에는 비교적 적은 비용과 시간이 소모되지만 Fine-tuning을 개발자가 직접 해주어야 하기 때문에 여기서 시간이 투자되고 비용이 발생한다. 그렇기 때문에 개발자는 Fine-tuning을 하는 곳에 더 초점을 맞추어야한다.
'Deep Learning > Natural Language Processing' 카테고리의 다른 글
| [NLP] Stemming and Lemmatization (0) | 2022.01.18 |
|---|---|
| [NLP] Tokenization (0) | 2022.01.18 |
| [NLP] Transformer (0) | 2021.10.21 |
| [NLP] Lexical Analysis (0) | 2021.07.20 |
| [NLP] INTRODUCTION (2) | 2021.06.26 |