NLP를 활용할 수 있는 분야에 대해서 공부해보는 파트이다.
자연어 처리를 활용할 수 있는 사례
- 자연어 처리는 질문에 대한 응답을 얻기 위하여 사용
- 음성을 인식하여 음성을 다른 언어로 바꿔주는 번역 및 소리로 변형(파파고, 구글 번역기, 아프리카TV 도네이션 등)
- image understanding : 이미지를 보여주고 그 이미지에 대해 질응
- Linguistic structure : 문장이 주어졌을 경우 알맞은 단어를 찾는 경우
단어에 대해서 분석을 하려면 단어들을 숫자들의 vector로 변형해주어야 한다. 주로 one hot vector로 변형을 해준다. 하지만 one hot vector 에는 여러가지 문제점이 존재한다.
- Sparsity : 굉장히 정보가 적다.
- Orthgonal representation : 단어들이 직교한다. (직교가 되면 계산하는데에 제약이 많다)
- Weakness in semantics : 단어들의 유사도를 찾을 때 단어들이 직교 되어 있으면 찾기가 힘들다.

이러한 one hot encoding의 문제점을 보완하기 위해 나온 접근법은 아래와 같다.
- Count-base
1. corpus에 있는 모든 단어 집합을 사용하는 것이 아니라 분석자가 선별한 단어 집합만을 사용하는 것
2. Stop-words 즉, 불용어를 제거하는 것 ( a, the, in 등등)
3. Lemmatization 단어들의 구문들을 하나로 바꾸어준다. (made -> make, went -> go)
4. 너무 많이 등장하지 않는 단어들은 제거
5. one - hot representation
one hot vector 대신 다른 vector를 바꿔주려면 사용하는 것이 Word window를 사용한다. Word window는 특정 단어 양 옆에 있는 단어들의 one hot vector를 더해서 정의할 수 있다. 다른 방법으로는 코사인 유사도가 있다. 코사인 유사도는 두 단어 사이의 유사도를 구할 수 있다. 만약에 one hot vector를 가지고 내적을 했을 경우는 0이 나올 것이다.
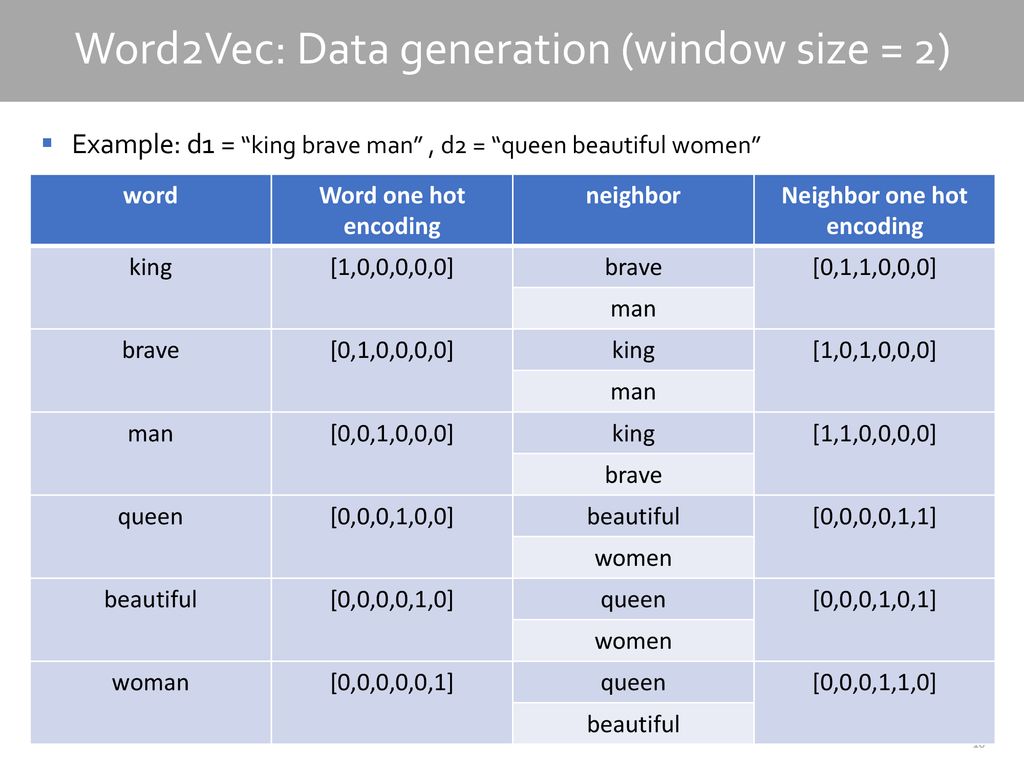

모든 단어들의 중요도는 전부 같지 않기 때문에 단어들의 중요도를 구해주는 measure이 존재한다.
1. TF-IDF
2. PMI ( 연관규칙의 lift와 비슷한 개념 )
- $ pmi(x,y) = \log{p(x,y) \over p(x)p(y)} $ 독립적인지 독립적이지 않는지를 확인
- Predictive
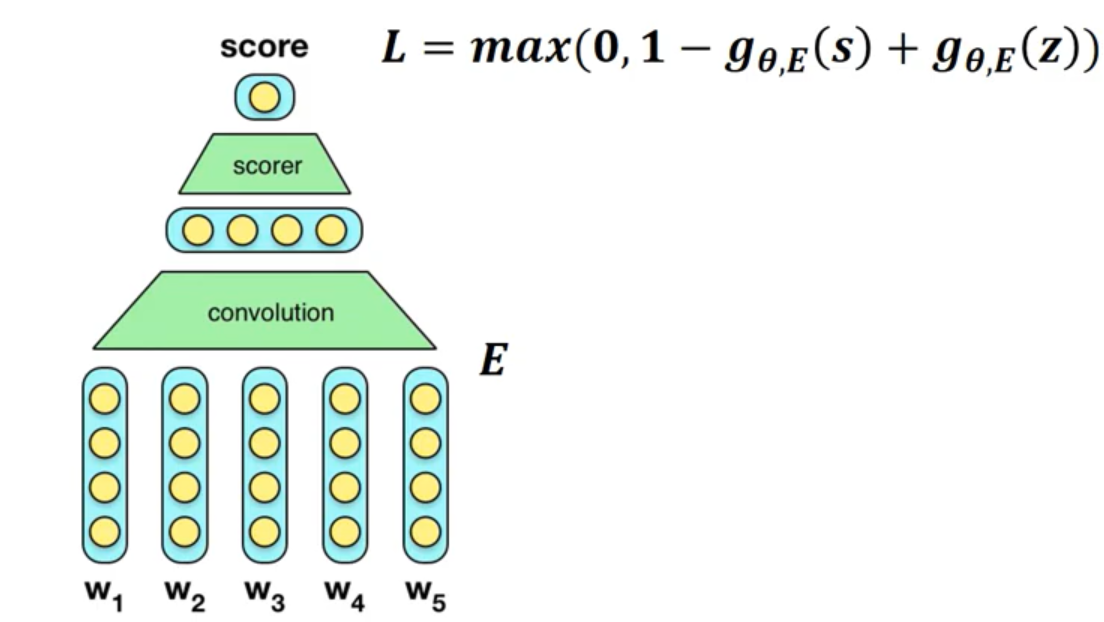
예측에 기반한 방법이며, 단어를 input으로 넣어주고 예측값을 통하여 words 값을 update 해주고 구해주는 작동 방식 각 단어들은 one hot vector 로 들어간다. Loss function에서 $g_{\theta,E}(z)$ 로 오염시켜 학습 결과가 Trivial하게 되는 것을 방지한다. Corruption 이 없으면 모델이 input에 관계 없이 무조건 high score를 반환하게 학습될 수 있기 때문이다. 하지만 Collobert et al. 2011에서 제안한 모델은 학습하기가 쉽지 않고, score의 뜻이 직고나적으로 불명확하다. 마지막으로 convolution이 너무 지엽적인, 중요하지 않은 정보만 표현할 수 있다.

위 모델의 문제점을 보완하여 나온 모델이 CBOW(Continuous Bag-of-Words)라는 모델이다. CBOW는 word들을 word window 방식으로 단어를 예측하여 Softmax함수를 사용해 출력하는 모델이다. CBOW는 속도가 빠르고, 단어 간의 의미 정보를 잘 담아낸다.
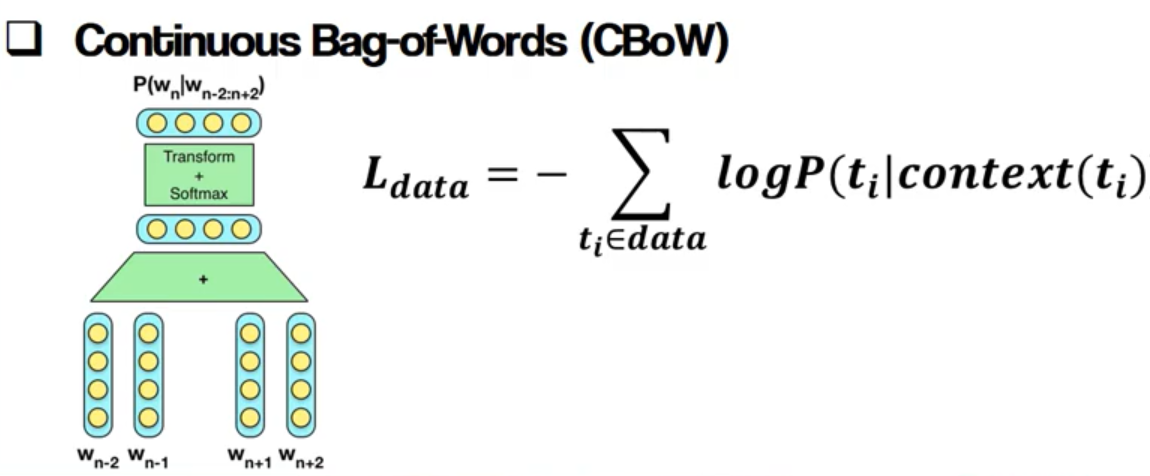
- task - based
주어진 목적을 해결하기 위한 모델과 word vector(embedding)을 연결하여 같이 학습(처음부터 혹은 사전학습) 앞과 같은 방식으로 word embedding을 한 다음에 embedding이라는 input을 task에 맞게 변형을 시킨다. 하지만 Task-based Word Embedding은 단어의 뜻을 깊이 학습하지 못하고, 목적에 의존적인 의미만 학습할 수 있다.
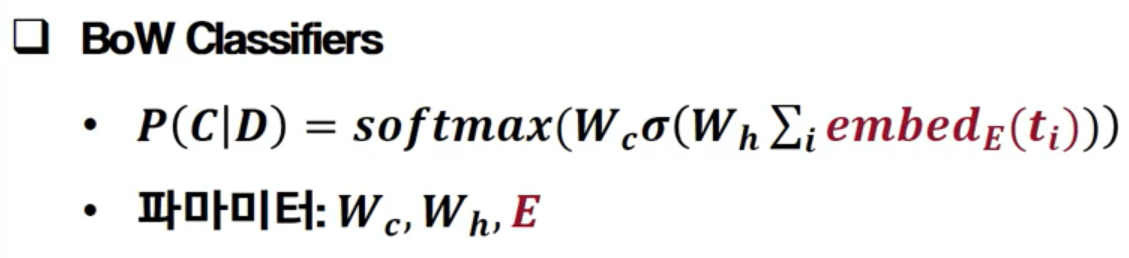
참고문헌
[1] 고려대학교 세미나
[2] OXford Deep NLP
'Deep Learning > Natural Language Processing' 카테고리의 다른 글
| [NLP] Stemming and Lemmatization (0) | 2022.01.18 |
|---|---|
| [NLP] Tokenization (0) | 2022.01.18 |
| [NLP] Transformer (0) | 2021.10.21 |
| [NLP] Lexical Analysis (0) | 2021.07.20 |
| [NLP] BERT (0) | 2021.06.26 |