Backpropagation 이 왜 Neaural Network에서 중요할까? Backpropagation 은 어떤 함수의 gradient를 계산하는 방식이다. chain rule를 recursively( 재귀적으로 ) 적용을 하고, 이러한 계산 방식이 computational 하다고 할 수 있다. backpropagation을 하는 가장 주된 목적은 parameter를 updata하기 위함이다. parameter를 update 하면서 가장 최적의 parameter를 찾는 것이 궁극적인 목적이기 때문이다. 부수적으로는 학습한 NN을 시각화하고 해석하기 위함이다.
NN 이라는 것은 하나의 함수라고 지칭할 수 있다. 만약 SVM을 이라면 convex optimization을 활용하여 단 한 번의 optimum을 하면 되기 때문에 gradient 방식을 사용할 필요가 없다. 하지만 NN은 multiple hidden layers를 가지고 있기 때문에 한 번의 optimum으로는 해결할 수 없게 된다. 그렇기 때문에 NN에서는 gradient 방식에 기반한 optimization을 사용한다.

우리는 $\partial f \over \partial z $의 도함수가 어떤 것인지 알고 싶은 것이 아니라 도함수의 값을 알고 싶은 것이다. 각각의 operate에 따라 다르게 표현해준다 . ( $\partial f \over \partial z $ $\partial f \over \partial x $ $\partial f \over \partial y $ ) 아래 빨간색은 도함수의 값으로 보면 된다.

이 개념을 알기 위해서는 chain rule을 알고 있어야 한다 .$\partial f \over \partial x $를 $\partial f \over \partial q $*$\partial q \over \partial x $ 형태로 바꾸어 주면서 operate 마다 단계별로 계산을 할 수 있기 때문이다. 지금 그림에는 두 가지 방식밖에 없지만 나중에 hidden layer가 많아지면 각개격파를 하는 식으로 계산을 하기 때문에 사용하기가 좋다. 작은 한 노드에 대한 gradient는 아래와 같다. 본 강의에서는 backpropagation을 각 gate간의 communicating이라고 표현하고 있다.

backprobagation 을 sigmoid function에 적용시켜서 한 번 다루어 보자.
위 내용과는 ( 덧셈, 곱셈 ) 말고 여러 operate를 볼 수 있다.
$f(w,x) = {1 \over 1 + e^{-w^{T}x} } = {1 \over 1 + e^{-(w_{0}x_{0}+w_{1}x_{1}+w_{2}x_{2})} } $
$ f(x) = {1 \over x} \Rightarrow$ ${df \over dx} -{1 \over x^{2}} $
$ f_{c}(x) = c\ +\ x \Rightarrow \ {df \over dx} = 1 $
$ f(x) = e^{x} \Rightarrow$ $ {df \over dx} = e^{x} $
$ f_{a}(x) = ax \Rightarrow $ $ {df \over dx} = a $
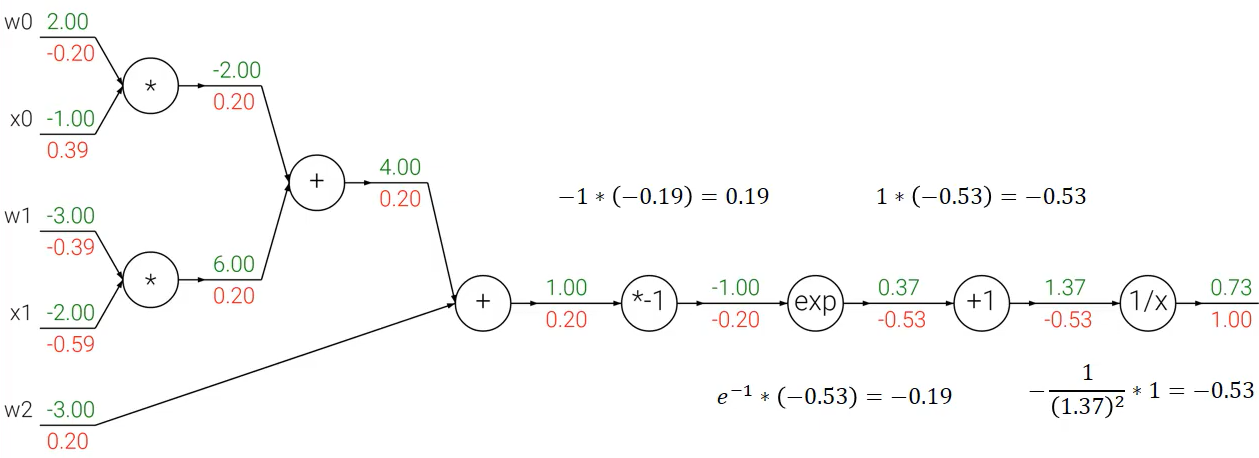
$w_{0}x_{0}+w_{1}x_{1}+w_{2}x_{2} $ 이 값들을 한 부분으로 묶고, 다음 부분을 한 값으로 묶으면
$ \sigma(x) = {1 \over 1 + e^{-x}} $
$ {d \sigma(x) \over dx} = (1- \sigma(x))\sigma(x) $
( 1 - 0.73 ) * 0.73 * 1 = 0.2
로 결과값이 나오는 것을 알 수 있다. 하나의 sigmoid gate로 보면 된다.
$ f(x, y) = xy $ 는 Gradient swapper 라고 부르고, $ f(x,y) = x + y $ 는 Gradient distributor 라고 부르기도 한다.
$ f(x, y) = max(x, y) $ x, y중 큰 값에 대해서만 1을 반환하는 Gradient router도 자주 쓰인다.
위 부분에서는 하나씩 들어오는 값들만 다루고 있는데 여러 갈래에서 들어오는 값이면 각각 더해서 미분해주면 된다.
딥러닝에서는 node가 많아서 gradient를 계산하려면 엄청 복잡해지지만 chain rule을 통해서 상당히 간단하게 계산을 할 수 있게 된다. intermediate values를 가지고 backpropagation을 할 수 있다.
'Deep Learning > CS231N' 카테고리의 다른 글
| [CS231N] Optimization의 종류 - SGD부터 Adam까지 (0) | 2021.07.12 |
|---|---|
| [CS231N] 활성화 함수(Activation Fucntion)의 종류 (0) | 2021.07.08 |
| [CS231N] Loss function & Optimization (2) (0) | 2021.07.05 |
| [CS231N] Loss function & Optimization (1) (0) | 2021.07.05 |
| [CS231N] Image Classification pipeline (0) | 2021.07.04 |