Training Neural Network
Transfer learning을 진행할 때 고려할 점.
1) Pre-train data와의 이질성
2) Finetuning할 데이터의 양
3) 분석에 할당된 시간
4) 가용한 hardware
...

하나의 layer에서 activation function으로 들어가게 되는데 layer의 값은
일반적으로 tensorflow API에서 Activation function을 제공해준다.
- tf.nn.relu(features, name = None)
- tf.nn.relu6(features, name = None)
- tf.nn.crelu(features, name = None)
- tf.nn.elu(features, name = None)
- tf.nn.softplus(features, name = None)
- tf.nn.softsign(features, name = None)
- tf.nn.dropout(features, noise_shape = None, seed = None, name = None)
- tf.nn.bias_add(features, bias, data_format = None, name = None)
- tf.sigmoid(x, name = None)
- tf.tanh(x, name = None)
Sigmoid
sigmoid는 3가지 문제점을 언급하고 있다.
1) sigmoid의 범위가 [0,1]이기 때문에 그래프의 중심이 0이아니다.
2) safety zone을 넘어가게 되면 gradient가 0이 되어 버린다.
' vanishing gradient problem ' 이 발생할 수 있다.
3)
tanh
sigmoid의 문제점을 보완하기 위해 도입된 activation function이라고 보면 된다. sigmoid문제 중에서 1번 문제를 해결할 수 있는 그래프이다.
하지만 아직도
ReLU ( Rectified Linear Unit )
앞선 sigmoid와 tanh와 달리
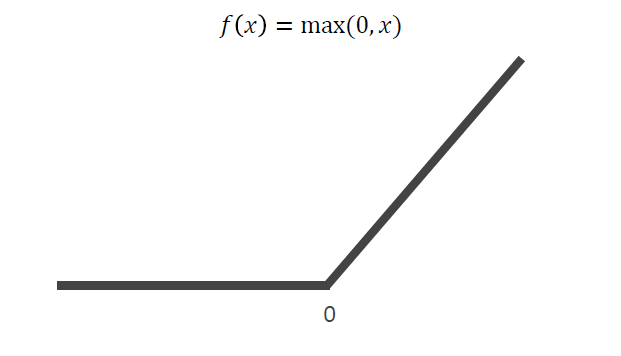
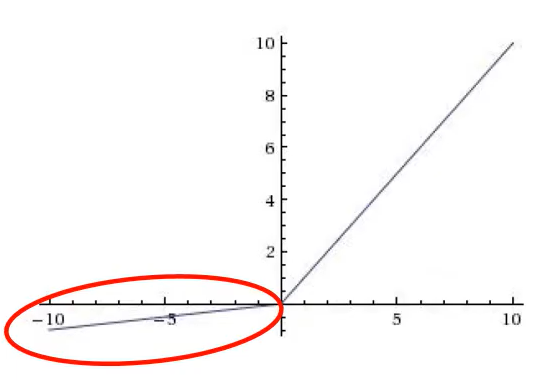
Leaky ReLU
ReLU에서 0인 부분에
Parametic Rectifier ( PReLU )
PReLU는
Exponential Linear Units (ELU)
ELU는 ReLU보다 성능이 좋고, gradient가 0 이되지 않고, output의 평균이 0 이 될 수 있는 등 여러가지 장점들이 있지만 다시

Q. 만약 우리가
A. 결론부터 말하자면 좋지 않다. 왜냐하면 backpropagation을 할 때 변화하는 양이 전부다 동일하게 출력된다.
1. node들의 개수가 많지만 node들의 값이 대부분 0으로 가있기 때문에 가치가 떨어진다.
2. 어떤 값이 있어서 backpropagation으로 계산을 한다 하더라도 gradient에 w를 곱해서 가게 되면서 gradient가 굉장히 작은 값이 도출된다.
weight의 들어오는 갯수와 나가는 갯수가 다른데 모든 상황에서 initialization 을 한다는 것이 과연 합당한가? 에 대해서 생각할 수 있고 그러한 문제에서 linear activation이라는 가정하에 Xavier initialization을 제안했다. 결국 Xavier initialization std이
import numpy as np
import matplotlib.pyplot as plt
D = np.random.randn(1000, 500)
hidden_layer_size = [500]* 10 # 10 : hidden layer, 500 : hidden node
nonlinearities = ['tanh'] * len(hidden_layer_size)
activate = {'relu' : lambda x : np.maximum(0, x), 'tanh' : lambda x: np.tanh(x)}
Hs = {}
for i in range(len(hidden_layer_size)):
X = D if i == 0 else Hs[i-1] # input at this layer
fan_in = X.shape[1]
fan_out = hidden_layer_size[i]
W = np.random.randn(fan_in, fan_out) * 0.01 # layer initialization
H = np.dot(X, W)
H = activate[nonlinearities[i]](H)
Hs[i] = H
Hs.items()
print ('input layer had mean %f and std %f' % (np.mean(D), np.std(D)))
layer_means = [np.mean(H) for i, H in Hs.items()]
layer_stds = [np.std(H) for i, H in Hs.items()]
for i, H in Hs.items():
print( 'hidden layer %d had mean %f and std %f ' % ( i + 1, layer_means[i], layer_stds[i]))
plt.figure()
plt.subplot(121)
plt.plot(Hs.keys(), layer_means, 'ob-')
plt.title('layer mean')
plt.subplot(122)
plt.plot(Hs.keys(), layer_stds, 'or-')
plt.title('layer std')
plt.figure()
for i, H in Hs.items():
plt.subplot(1, len(Hs), i+1)
plt.hist(H.ravel(), 30, range = (-1, 1))
plt.show()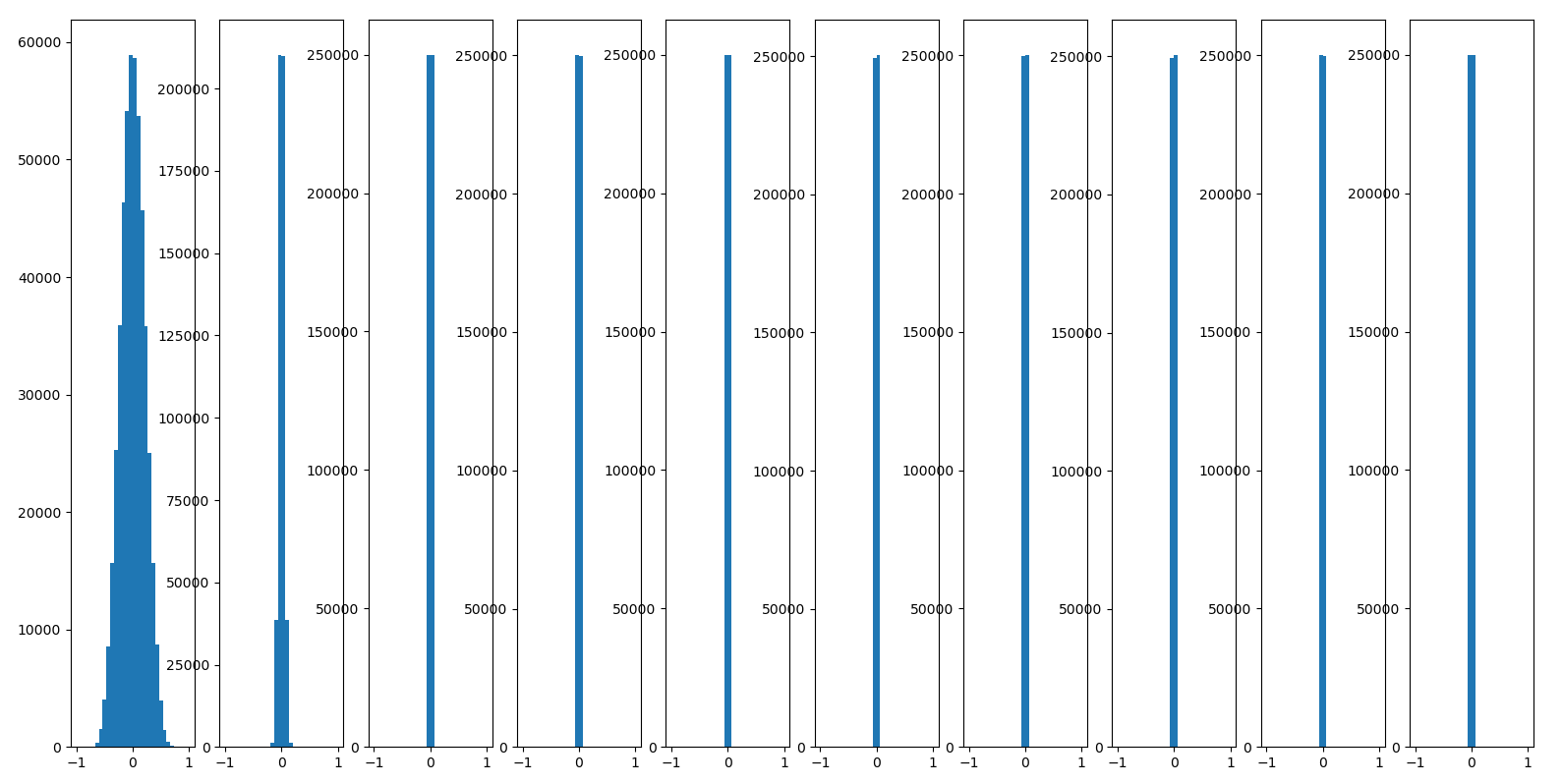
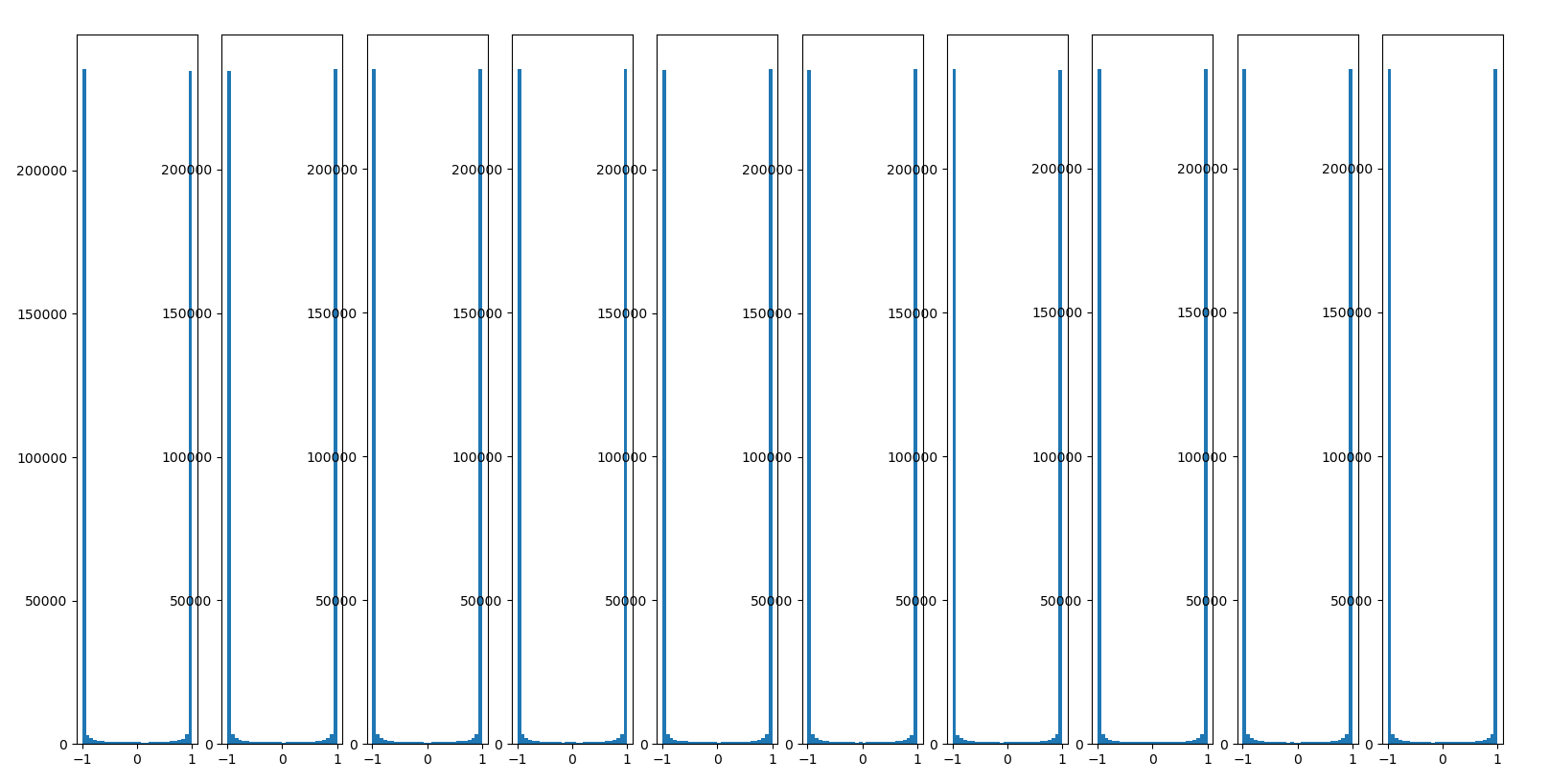
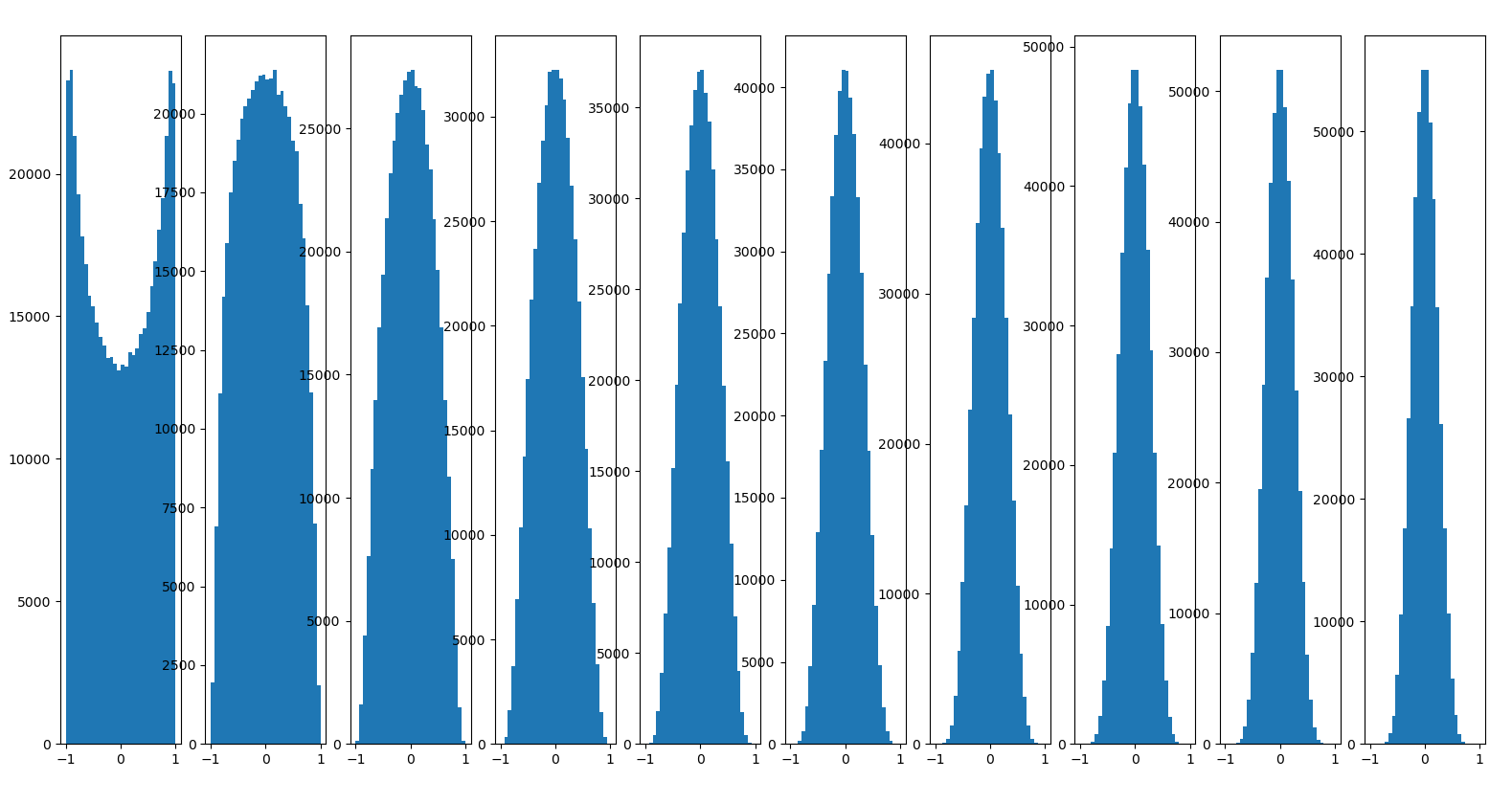
Batch Normalization
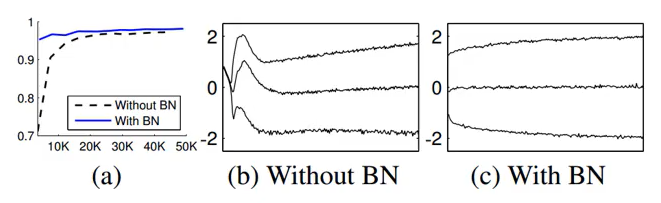
Batch Normalization은 CNN에서 거의 default로 사용하는 알고리즘이라고 할 수 있다. 상식적으로 생각을 해보았을 때 계속 Batch단위로 training을 하게 되면 분포가 변화하게 된다. 심지어 1번 layer에서 적은값으로 변하게 되어서 뒷 부분에서는 큰 값으로 변해야 된다면, Shifting 값이 점점 심해질 수 밖에 없다. 그 부분을 보정하고자 Batch Normalization이 나왔다. 아래 식에서의
BN의 장점
- 높은 learning rate도 수용할 수 있다.
- network를 통한 gradient flow가 향상된다.
- initialization 의 dependence도 줄어든다.
- regulazation 기능을 한다.
- dropout의 필요성도 줄어든다. ( dropout : hidden layer의 일부 유닛이 동작하지 않게 하여 overfitting을 막는 방법 )

Batch Normalization을 진행할 때, initialization 값으로
제일 처음 시작할 때는
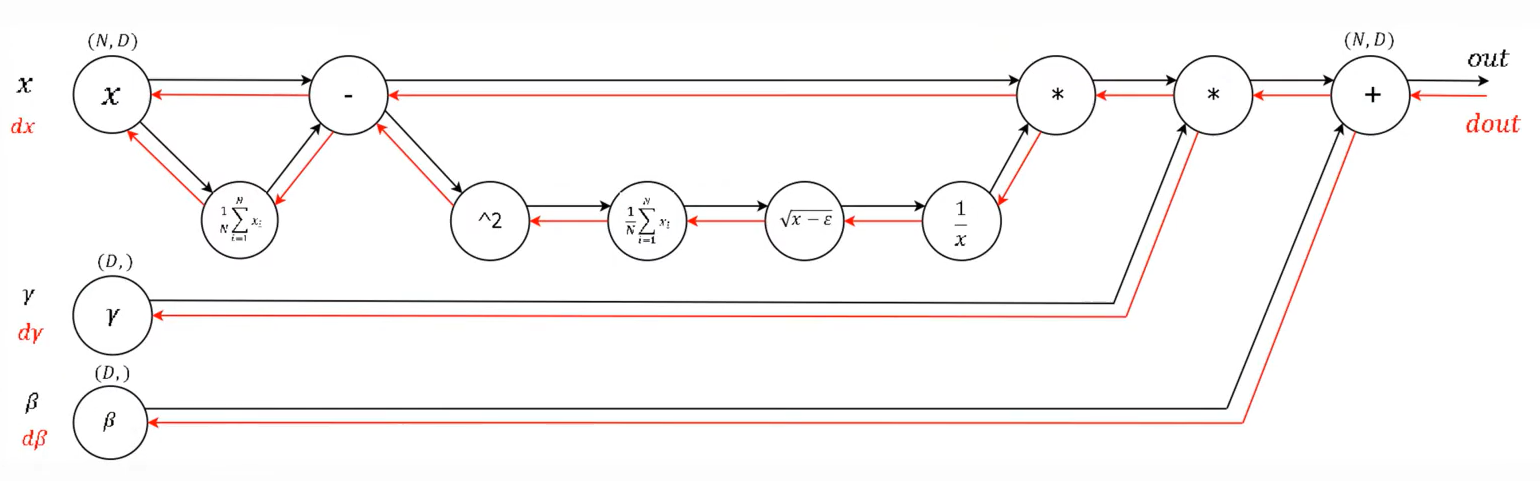
import numpy as np
# forward
def batchnorm_forward(x, gamma, beta, eps):
N, D = x.shape
# step1 : calculate mean
mu = ( 1. / N ) * np.sum(x, axis = 0)
# step2 : subtract mean vector of every training example
xmu = x - mu
# step3 : following the lower branch - calculation denominator
sq = xmu ** 2
# step4 : calculate variance
var = ( 1. / N ) * np.sum(sq, axis = 0)
# step5 : add eps for numerical stability, then sqrt
sqrtvar = np.sqrt(var + eps)
# step6 : invert sqrtwar
ivar = 1. / sqrtvar
# step7 : execute normalization
xhat = xmu * ivar
# step8 : Nor the two transformation steps
gammax = gamma * xhat
# step9
out = gammax + beta
cache = (xhat, gamma, xmu, ivar, sqrtvar, var, eps)
return out, cache
# backward
def batchnorm_backward(dout, cache): # local gradient
# unfold the variable stored in cache
xhat, gamma, xmu, ivar, sqrtvar, var, eps = cache
# get the dimentions of the input / output
N, D = dout.shape
# step 9
dbeta = np.sum(dout, axis = 0)
dgammax = dout
# step 8
dgamma = np.sum(dgammax * xhat, axis = 0 )
dxhat = dgammax * gamma
# step 7
divar = np.sum(dxhat * xhat, axis = 0 )
dxmu1 = dxhat * ivar
# step 6
dsqrtvar = -1. / (sqrtvar ** 2) * divar
# step 5
dvar = 0.5 * 1. / np.sqrt(var + eps) * dsqrtvar
# step 4
dsq = 1. / N * np.ones( (N, D) ) * dvar
# step 3
dxmu2 = 2 * xmu * dsq
# step 2
dx1 = (dxmu1 + dxmu2)
dmu = -1 * np.sum(dxmu1 + dxmu2, axis = 0 )
# step 1
dx2 = 1. / N * np.one( (N, D) ) * dmu
# step 0
dx = dx1 + dx2
return dx, dgamma, dbeta
'Deep Learning > CS231N' 카테고리의 다른 글
| [CS231N] Convolution Neural Networks(CNN) (2) | 2021.07.14 |
|---|---|
| [CS231N] Optimization의 종류 - SGD부터 Adam까지 (0) | 2021.07.12 |
| [CS231N] Neural Network Back-propagation (0) | 2021.07.06 |
| [CS231N] Loss function & Optimization (2) (0) | 2021.07.05 |
| [CS231N] Loss function & Optimization (1) (0) | 2021.07.05 |