경사법 ( 경사 하강법 )
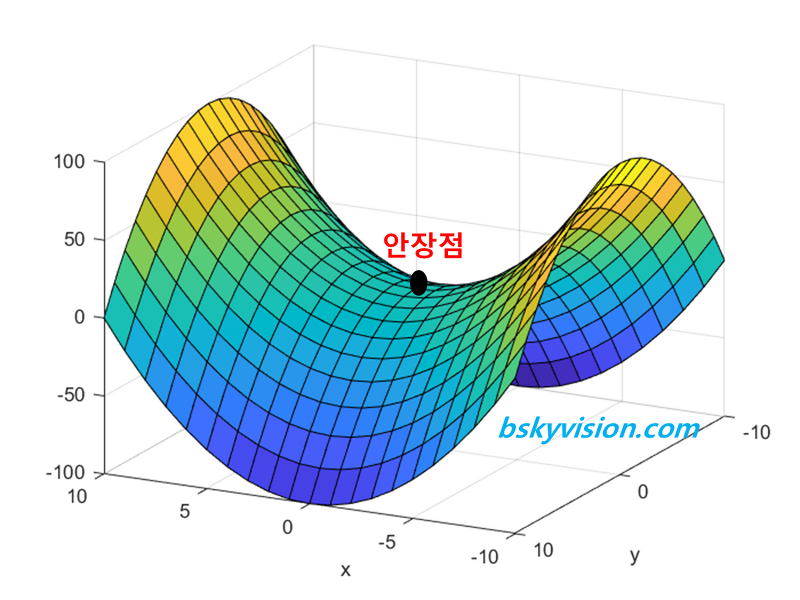
신경망에서 최적의 매개변수를 학습 시에 찾아야 한다. 최적이란 손실 함수가 최솟값이 될 때의 매개변수 값이다. 하지만 매개변수의 공간이 광대하여 최솟값을 찾는데에 있어 어려움이 있기 때문에 경사하강법을 사용하여 최솟값을 찾으려고 한다. 하지만 그 기울기가 가리키는 곳에 정말 함수의 최솟값이 있는지 보장할 수 없다(안장점). 실제로 복잡한 함수에서는 기울기가 가리키는 방향에 최솟값이 없는 경우가 대부분이다. 경사법은 현 위치에서 기울어진 방향으로 일정 거리만큼 이동하는 것을 말한다. 그런 다음 이동한 곳에서 다시 기울기를 구하고, 또 기울어진 방향으로 나아가기를 반복한다. 이 방법은 특히 신경망 학습에 많이 사용된다.
$x_{0} = x_{0} - \eta {\partial f \over \partial x_{0}} $
$x_{1} = x_{1} - \eta {\partial f \over \partial x_{1}} $
여기서 $\eta$는 갱신을 하는 양을 나타낸다. 신경망에서는 학습률을 지칭한다. 위 식은 1회에 해당하는 갱신이고 이 단계를 계속 반복을 통해서 함수의 값을 줄여나가는 것이다. 위 식에서는 변수가 2개인 경우를 보여줬지만, 변수가 늘어나도 각 변수의 편미분 값으로 똑같이 갱신을 하면 된다. 학습률 또한 사전에 0.01 이나 0.001 등 값을 정해두어야 하는데, 일반적으로 학습률이 너무 크면 '좋은 장소'를 찾아갈 수 없다. 경사법을 아래와 같이 정의 했다.
import numpy as np
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
x[idx] = tmp_val + h
fxh1 = f(x)
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val
return grad
def gradient_descent(f, init_x, lr = 0.01, step_num = 100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
def function_2(x):
return x[0]**2 + x[1]**2
init_x = np.array([-3.0, 4.0])
gradient_descent(function_2, init_x = init_x, lr = 0.1, step_num = 100)
# array([-6.11110793e-10, 8.14814391e-10])
Gradient Descent methods
Gradient Descent에서도 종류가 다양하다. 여기서 가장 기본이 되는 Method는 Stochastic gradient Descent가 된다. SGD라고도 표현하며, 각 simgle sample에 대해서 기울기를 계산하는 방식이다. Mini-batch gradient descent는 일반적으로 딥러닝에서 사용할 때 DataLoader에 담아서 batch_size만큼 학습(16, 32, 64, 128, ...)하는 미니배치 사이즈 만큼 학습해 나오는 cost를 평균을 취해 기울기를 계산하는 것을 의미하고 Batch gradient descent는 10만개의 데이터가 있으면 그 데이터를 전부 평균을 취해서 기울기를 계산하는 것을 의미한다.
Batch로 두어 한 번에 데이터를 학습하게 되면 GPU가 터져버리기 떄문에 mini-batch를 통해 분할하여 계산하는 것이라고 단순히 생각해 batch_size가 큰 하이퍼파라미터가 아니라고 생각할 수 있지만, batch size는 중요한 하이퍼파라미터 중 하나이다.
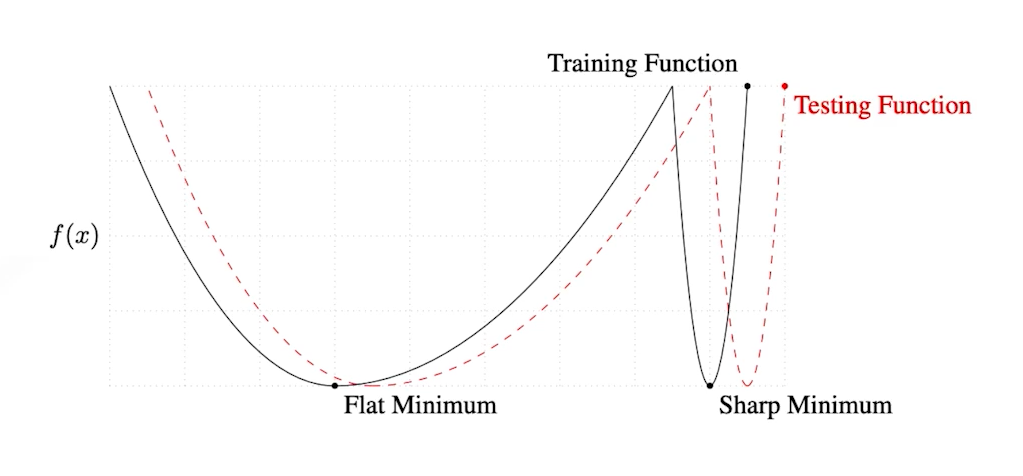
On Large-batch Training for Deep Learning : Generalization Gap and Sharp Minima, (2017)에 의하면 너무 큰 배치 사이즈를 가지면 sharp minimizers에 converge하는 경향이 있고, 그에 반해 작은 배치 사이즈를 가지고 학습을 하게 되면 flat minimizer에 도달한다. 해당 논문에서는 sharp minimizer에 도달하는 것 보다는 flat minimizer에 도달하는 것이 더 좋다라는 것을 말하려고 한다.
우리는 결론적으로 바라본다면 Testing function에서의 minimum을 찾고 싶어한다. 아래의 그림에서 Flat minimum에 도달할 경우에는 testing function의 minimum과 training function의 minimum이 차이는 있지만 큰 차이는 보이지 않고 있다. 하지만 sharp minimum의 경우를 본다면 뾰족하게 생겼기 때문에 training Function에서는 minimum이지만 testing function에선느 maximum에 해당하는 값이 출력될 확률이 더 커지게 된다.
해당 논문에서는 우리가 만약 큰 배치사이즈로 모델을 학습시키기 위해서는 어떠한 과정들이 필요한가에 대해서 실험적으로 다루는 논문이다. 만약 큰 배치 사이즈로 모델을 학습시켜야하는 경우에는 여기 논문을 참고하는 것이 좋을 것 같다.
우리가 파이토치나 텐서플로우를 통해 모델을 학습시킬 때 optimizer를 직접 손으로 계산하는건 너무 어렵고, 복잡하고, 시간 낭비기 때문에 그렇게 하지는 않는다. 파이토치나 텐서플로우는 자동으로 미분을 계산해주는 좋은 모듈들이 존재한다.( 파이토치 )
해당 패키지에서 제공해주는 SGD, Momentum, Adagrad, Adam 등 최적화 모듈 중 하나를 골라야한다. 각각이 왜 제안되었고 어떤 성질이 있는가를 알아두면 좋다.( CS231N 강의를 통해 정리를 해두었다.)
최적화를 할 때 learning rate가 너무 커도 학습이 되질 않고, learning rate가 너무 작아도 학습이 잘 되지 않기 때문에 적절한 learning rate를 찾는 것 역시 좋은 모델을 만드는데 있어서 하나의 요소가 된다.
'Deep Learning > Optimization' 카테고리의 다른 글
| [Optimization] Important Concepts in Optimization (0) | 2021.10.19 |
|---|