최적화에서도 여러가지 방법이 있지만 여기서는 머신러닝, 딥러닝에서 활용되는 최적화 기법과 기본적인 모델에 대해서 다뤄볼 것이다. 우리는 모델의 Generalization 성능을 높이는 것이 목표다. 하지만 우리가 무조건적인 일반화를 하는 것이 좋은 모델인가?
iteration을 반복하게되면 학습데이터에 대해서 계속 학습을 하기 때문에 training error는 지속적으로 줄어들게 된다. training error가 0이 되었다고 해서 모델의 일반화가 되었다고는 말할 수 없다. 왜냐하면 너무 training data에 적합한 모델이 되어버려서 일반화가 되지 않아, training 되지 않은 새로운 dataset에서는 모델이 적절하지 않기 때문이다. 너무 과적합 되어버리면 test set에서는 오히려 error가 커진다.
Generalization performance
training error가 최소가 되며 test error 역시 낮아지는 지점을 찾아야된다. Generalization performance라는 것은 일반적으로 test error와 train error 간의 차이를 말하는 것이며, 해당 모델이 좋은 Generalization performance를 가지고 있다라는 의미는 해당 네트워크 성능이 학습데이터의 성능과 비슷한 성능이 나올 것이라는 것을 보장한다는 의미다.
하지만 Generalization performance가 좋다고 하더라도 모델 자체의 성능은 좋다고 할 수 없다. 왜냐하면 Generalization performance는 단지 test error와 train error간의 차이만을 의미하는 것이고, 만약 train error 자체의 성능이 좋지 않다면 해당 모델은 좋은 성능을 가진 모델이라고 할 수 없기 때문이다.
Underfitting vs Overfitting

Overfitting은 training set 에 너무 적합해져서 Generalization gap 이 커지는, 즉 test error가 높아지는 경우를 말한다. Underfitting은 네트워크 자체가 너무 간단하거나, training 자체의 epoch을 너무 적게 해서 학습 데이터 자체도 잘 맞추지 못하는 경우를 말한다. 위 그림은 단순한 회귀모델에서의 경우를 이미지로 보여준 것이고, 딥러닝에서의 모델과는 다소 차이가 있을 수 있다. 딥러닝은 nonlinear function을 활용해 오른쪽 overfitting과 같은 그래프를 target으로 하는 형태를 가질수도 있기 때문이다.
Cross-validation

보통은 학습데이터로 학습을 시키고 학습데이터로 학습시킨 모델의 성능을 Validation set을 통해 어느정도 성능이 나왔는지 검증을 한 후 test set에다 적용을 시킨다. 그럼 Train, Validation, test set은 얼마만큼으로 나누는 것이 적합한가? 5:5로 나누게 되면 좋을까? 좋을수도 있지만 training set 자체가 너무 적기 때문에 성능이 덜나올수도 있다. 이러한 문제를 해결하기 위해서 Cross-validation(K-fold)라고하는 교차검증법을 활용한다.
5개의 분할로 나누었다고 가정하면 1번셋을 validation set 으로 하고 나머지 4개의 셋을 training set으로 둔 후 학습에 적용시킨다. 그 후 2번 셋을 validation set으로 하고 나머지 1,3,4,5 셋을 training set으로 둔 후 학습하는 과정을 총 5번 반복하며 학습을 진행한다. 일반적으로 Cross-validation은 최적의 하이퍼파라미터 셋을 찾고, 찾은 후 하이퍼 파라미터를 고정시키고 모든 데이터를 학습하는 방식으로 진행한다. 절대 test set은 어떤 식으로든 활용해서는 안된다.
추가로 말하자면 TimeSeries에서는 Cross-validation을 활용하지 않는데 크게 두 가지 이유가 존재한다. 첫번째로는 시계열 데이터는 시간에 대해서 종속성을 가지기 때문이다. 만약 시계열 데이터에 Cross-validation을 활용하려면 hold-out을 통해 시간적으로 분할시켜 분석 방법이 이루어 져야된다. 두번째로는 테스트 세트의 임의 선택을 해버리는 것이다. 우리는 hold-out 을 통해 test set을 임의로 선택해버리는 과정에 있어서 문제가 많기 때문이다. 그렇기 때문에 Nested CV라는 파라미터 튜닝을 위한 inner loop를 추가한 모델을 사용한다.
보다 자세한 내용은 여기를 참고하시길
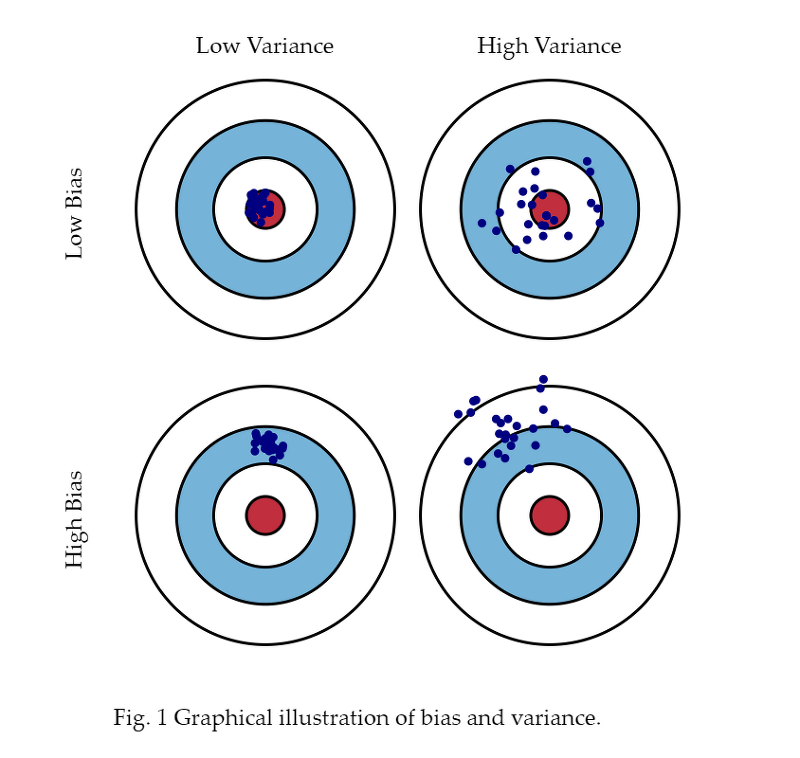
Bias and Variance
Bias와 Variance는 앞선 내용에서 언급한 underfitting과 overfitting과 이어진다. 과녁에 화살을 쏘았을 때 항상 같은 곳에 찍히면, 그 곳이 원점이 아니라 하더라도 같은 곳에만 찍히면 해당 부분을 전체적으로 shifting하면 좋은 결과를 도출해낼 수 있기 때문이다. 이 경우를 Low Variance라고 한다. Low Variance라는 것은 내가 어떤 결과를 넣었을 때 얼마나 출력이 일관적으로 나오는가에 대한 것이다. 비교적 간단한 모델이 Low Variance의 형태로 출력이 된다. 그에 반해 High Variance는 비슷한 입력이 들어와도 출력이 많이 달라지는 것을 의미한다. 이렇게 되면 오버피팅이 될 가능성이 크다.
Bias는 평균적으로 봤을 때 해당 값들이 True target에 접근하게 되면 그 자체로 Bias가 낮다고 하며, Bias가 높다라는 의미는 내가 얻고자 하는 어떠한 타겟과 멀어진다는 것을 의미한다.
모델의 cost를 minimizing하는 것은 하나의 값을 최소화 하는 것인데 cost는 총 3가지로 구성되어 있는데 우리는 최소화를 할 떄 3가지의 값을 전부 최소화 하는 것이 아니라 하나가 줄어들면 나머지들은 커질 수 밖에 없다라는 Trade off 를 가지고 있다.
만약 우리가 모델에서 Bias를 줄이려고 노력한 모델은 상대적으로 Variance가 클 가능성이 높고, 반대로 Variance를 최소화하는 모델은 Bias가 커질 가능성이 높다는 것을 의미한다. 우리의 데이터 셋에 noise가 껴 있을 경우에는 Variance와 Bias를 둘다 줄일 수 있는 모델은 사실상 얻기가 힘들다.
Bootstrapping
붓스트랩은 가설 검증을 하거나 메트릭을 계산하기 전에 random sampling을 적용하는 방법이다. (이때 random sampling은 중복을 허용해야한다.) bootstrapping은 데이터 셋내의 데이터의 분포가 고르지 않을때도 사용된다. 만약 A라벨의 데이터는 1만개, B라벨의 데이터는 500개가 있다고 하면 균형이 맞지 않을 경우 A이미지만 예측하는 모델이 있다 할지라도 좋은 성능을 보일 수 있다. 균형이 맞지 않는 경우 적은 클래스의 error는 무시되는 방향으로 트레이닝 된다.
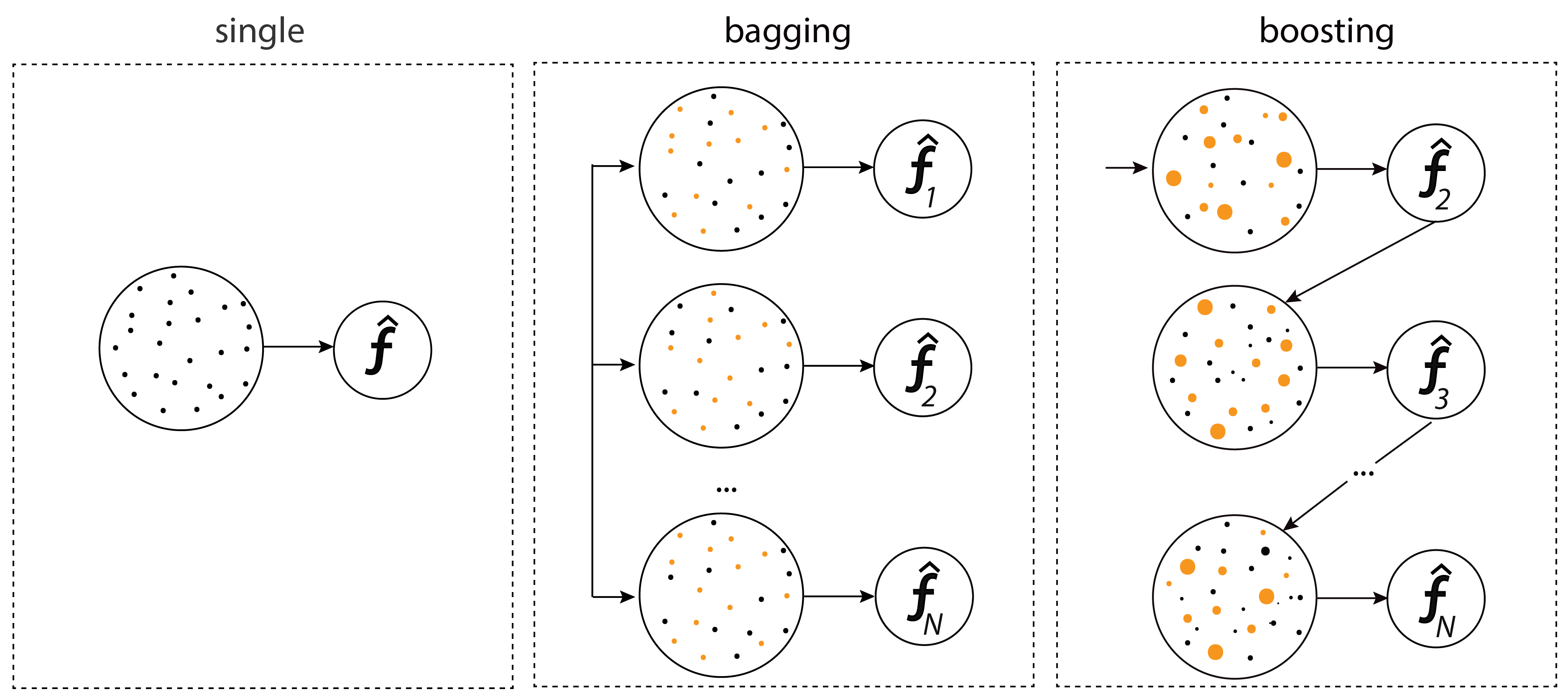
bootstrapping은 전체 데이터 셋에서 일부를 random sampling해서 만든 여러 모델들 간의 성능이 얼마나 일치하는가 판단하기 위한 것이며 bootstrapping내에서는 bagging과 boosting으로 나뉜다.
조금 더 상세한 내용이 궁금하다면 [여기]
Bagging vs Boosting
Bagging(Bootstrapping aggregating)은 학습데이터가 고정되어 있을 때 학습데이터를 모두 사용해서 하나의 모델을 만드는 것이 아니라 random sampling을 통해 여러개의 모델을 만들어 여러 모델들을 가지고 output들의 평균 혹은 voting을 낸다는 것이 bagging의 이론이다.
Boosting은 sequenctial한 느낌을 가지고 있다. 예를 들어 학습데이터가 100개 있으면 한 80개의 데이터 셋에는 잘 돌아가는 모델을 간단하게 만든다. 그 후 잘 학습이 안되는 20개의 모델에 제대로 작동할 수 있도록 모델을 새로 만든다. 그 후 모델을 합치게 되는데 기존에 만든 모델을 독립적인 형태로 n개를 뽑는 것이 아니라 weak learner를 Sequential하게 합쳐서 하나의 strong learner를 만든다. 각각의 weak learner들의 weight를 찾는 식으로 정보를 추합한다.
bagging 혹은 boosting을 활용해 overfitting을 방지하는 형태로 사용된다. bagging의 경우 variance를 감소시키는 역할을 하고 boosting의 경우 bias를 감소시키는 역할을 한다. bagging의 대표적인 모델은 Randomforest이며, boosting의 대표적인 모델은 XGBoost다. boosting은 bagging과 달리 병렬적인 앙상블 방법이 아니고 순차적인 앙상블 기법이며 이전에 학슴된 모델에 의해 조절되는 특성을 지닌다.
'Deep Learning > Optimization' 카테고리의 다른 글
| [Optimization] Gradient Descent (0) | 2021.07.07 |
|---|