Parsing 이란?
parsing은 각 문장의 문법적인 구성 또는 구문을 분석하는 과정이다. Constituency Parsing은 문장의 구조를 파악하는 것이 주목적이고, Dependency Parsing은 단어간 관계를 파악하는 것이 주목적이다.
Constituency Parsing
Constituency Parsing은 구 구문분석이라고도 불리며, 문장을 중첩된 성분으로 나누어 문장의 구조를 파악하며, 영어와 같이 어순이 비교적 고정적인 언어에서 주로 사용된다. 아래 예시를 보면 첫 번째로 John이라는 주어(N)와 hit the ball이라는 동사구(VP)로 나눌 수 있고, 동사구는 다시 hit라는 동사(V)와 The ball이라는 명사구(NP)로 나눌 수 있고, the(D)와 ball(N)로 나눌 수 있다.

Dependency Parsing
Dependency Parsing은 의존 구문분석이라고도 불리며, 각 단어간 의존 또는 수식 관계를 파악하며, 한국어와 같이 자유 어순을 가지거나 문장성분이 생략 가능한 언어에서 선호된다. 하지만 영어권에서도 점차 Dependency Parsing에 대한 관심이 증가하고 있다. Dependency Parsing에서는 수식을 받는 단어에서 수식을 하는 단어로 화살표가 가는데, 개별 단어간의 관계를 파악해서 단어 간 화살표를 표현하는데 그 화살표 위 어떤 라벨을 붙혀줄 것인가 결정하는 것이 output이다. 수식을 받는 단어를 head, governor이라 하고, 수식을 하는 단어를 dependent, modifier라고 부른다.

CS224N의 chapter 5 에서는 Dependency Parsing 에 관해서만 다루고 있기 때문에 Dependency Parsing에 관해서 알아보자. 우리는 Parsing이 왜 필요한가에 대한 의문점이 생길 수 있는데, CS224N에서는 Coordination Scope Ambiguity 관점에서 Parsing의 중요성을 설명하고 있다.
Coordination Scope Ambiguity
특정 단어가 수식하는 대상의 범위가 달라짐에 따라서 중의적으로 해석되는 것. 한글에서는 '작용역 중의성'이라고 불린다. 다음과 같이 Fred Gregory인 수식을 받는 단어가 어떠한 단어의 수식을 받는가에 따라서 문장의 의미가 달라진다. 'Shuttle veteran and longtime NASA executive'의 긴 문장을 수식으로 받게 되는 경우와 'longtime NASA executive' 의 수식으로 받게 되는 경우 문장의 해석이 달라지는 것을 볼 수 있다. 우리가 문장에 대해서 Parsing을 제대로 할 수 있다면 이런 문장의 모호성을 해결할 수 있다는 것이 Dependency Parsing이 필요한 이유라고 할 수 있다.

Phrase Attachment Ambiguity
형용사구, 동사구, 전치사구 등이 어떤 단어를 수식하는지에 따라 의미가 달라지는 것에서 기인하는 언어의 모호성이다. 아래의 예시를 보면 나라는 주어가 망원경을 통해서 소녀를 본 것인지 망원경을 가지고 있는 소녀를 본 것인지 모호하기 때문에 'saw'라는 단어가 with라는 단어의 식을 받는지와 같은 경우 Parsing을 통해 모호성을 없앨 수 있을 것이다.

인간은 복잡한 생각을 전달하기 위해 작은 단어를 큰 단위로 조합하며, 이러한 언어를 올바르게 이해하기 위해서는 문장의 구졸르 이해해야 한다. 즉, 무엇과 무엇이 연결되어 있는지에 대한 이해가 필요하다.
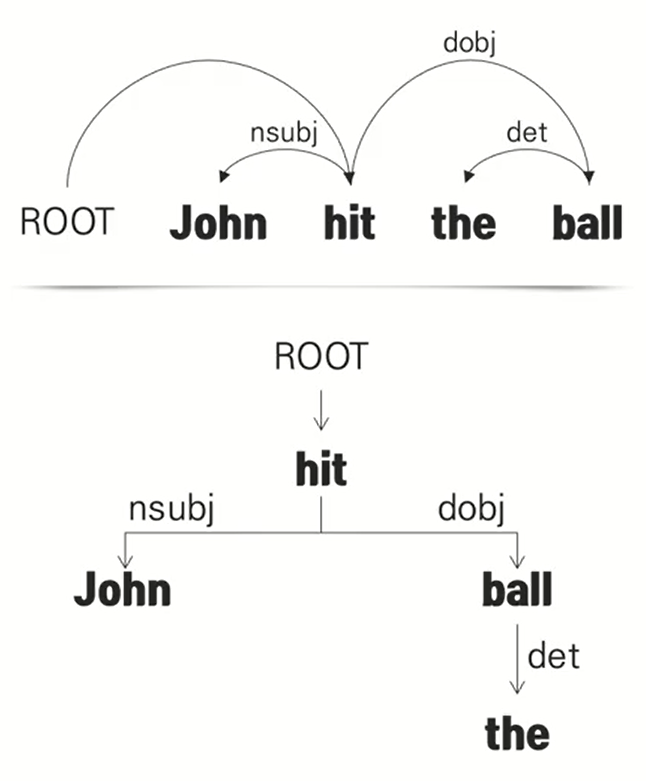
- Dependency Parsing의 Structure는 두 가지 형태로 표현이 가능하다.
- 일반적으로 사용하는 input sequence 구조에 ROOT라는 가상의 token을 이어붙혀 어떤단어를 수식하는지 윗단 화살표를 통해 표현하는 방식.
- TREE 형태로 화살표를 표현.
- 화살표는 head에서 dependent로 향한다. ( 수식을 받는 단어에서 수식을 하는 단어로 ) 영어에서는 수식을 하는 단어에서 수식을 받는 단어로 화살표가 움직였는데 dependency parsing에서는 dependency parsing을 처음 사용한 저자가 이런 방식으로 사용을 했기 때문에 수식을 받는 단어에서 수식을 하는 단어로 화살표가 움직이게 된다.
- 화살표 위 label은 단어간의 문법적 관계(dependency)를 의미한다. (nsubj : 주어, dobj : 직접 목적어, det : 한정사)
- 어떠한 단어의 수식도 받지 않는 단어는 가상의 node인 ROOT의 dependent로 만들어 모든 단어가 최소한 1개 node의 dependent가 되도록 한다.
- 화살표는 순환하지 않으며(if A $\rightarrow B,\ then\ B \nrightarrow A)$, 덕분에 parsing 결과물을 tree 형태로 표현할 수 있다.
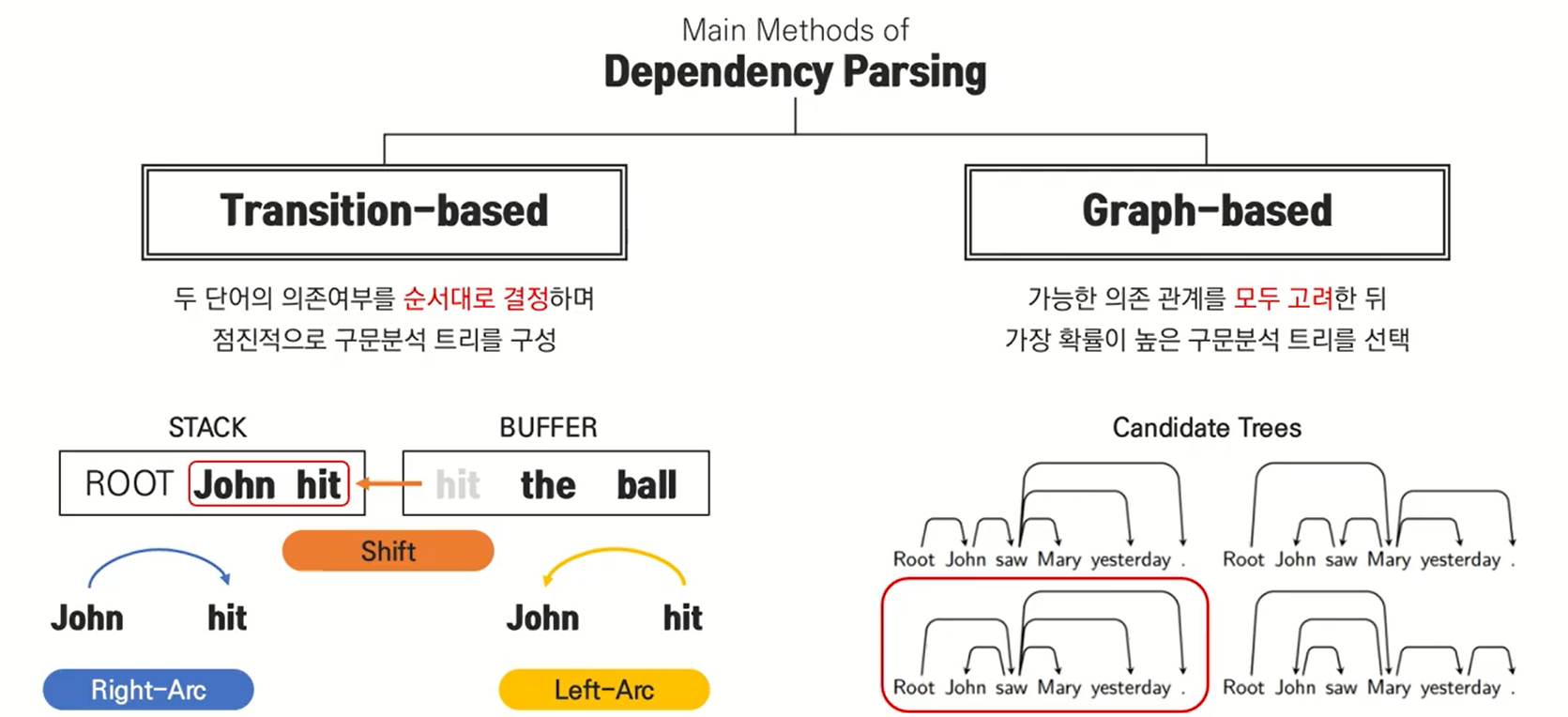
Dependency Parsing 에는 두가지 방법론이 있다.
1. Transition-based
두 단어의 의존여부를 순서대로 결정하며 점진적으로 구문분석 트리를 구성
- Joakim Nivre(2003)에 의해 고안됨
- Graph-based 방법론에 비해 상대적으로 속도는 빠르지만 정확도는 낮음
- Chen and Manning(2014)에서 dense feature를 사용한 신경망 기반 transition-based parser를 제안하여 속도와 성능 모두를 향상시킴.
- 현재는 다시 신경망 기반 Graph-based parser가 가장 높은 성능을 기록하고 있음.
2. Graph-based
가능한 의존 관계를 모두 고려한 뒤 가장 확률이 높은 구문분석 트리를 선택.
- 모든 경우를 고려하기 때문에 정확도가 높음
CS224N에서는 Transition-based에 중점을 두고 강의를 진행하기 때문에, Transition-based에 대한 자료를 가지고 정리하였다.
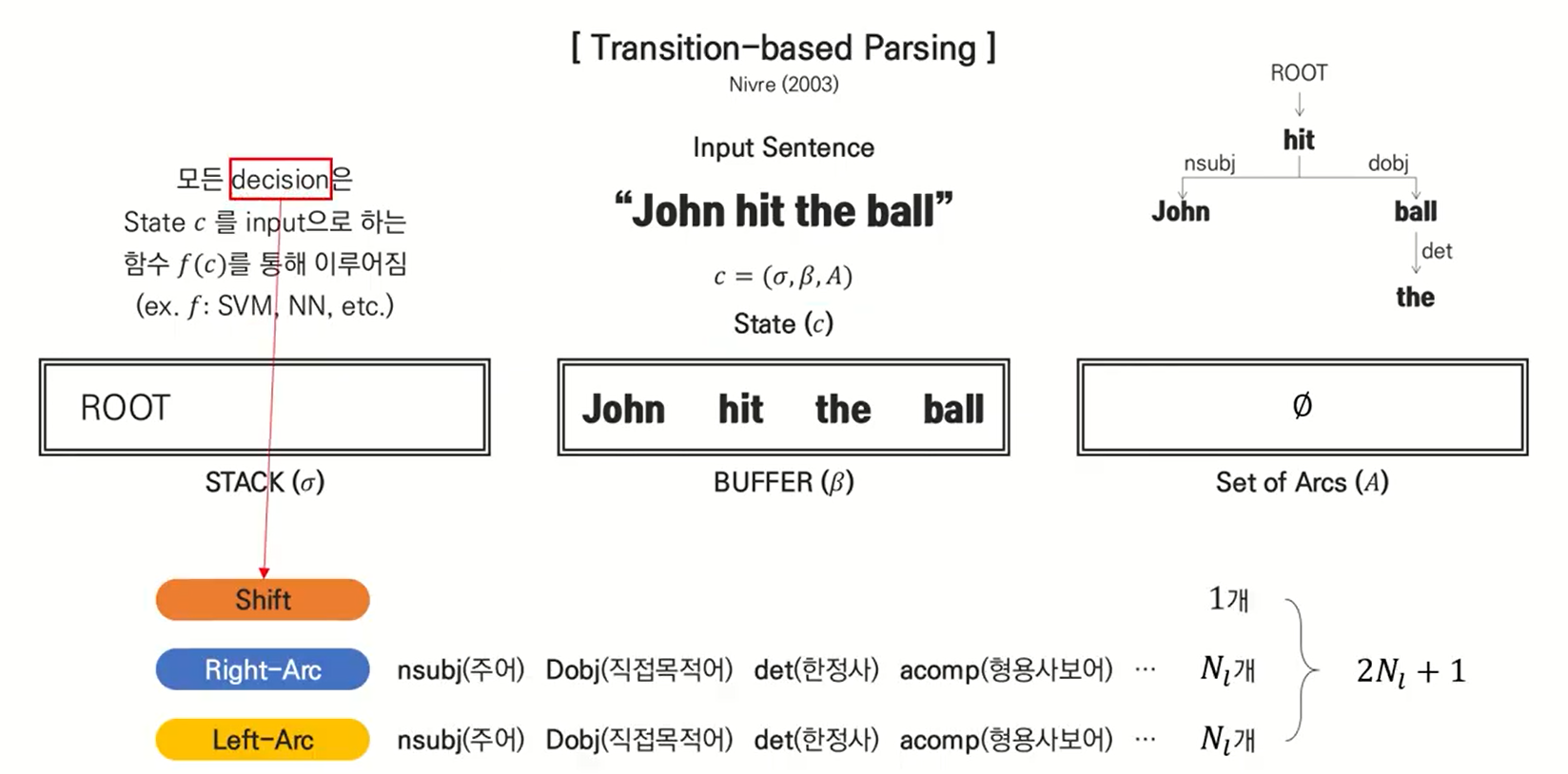
Transition-based
transition-based에서는 Shift, Left-Arc, Right-Arc 연산이 존재한다. Shift 연산은 BUFFER($\beta$)에서 STACK($\sigma$)로 가는 연산을 말하며, Left-Arc 와 Right-Arc는 수식받는 단어와 수식하는 단어의 관계를 표현해주는 연산이라고 볼 수 있다. 해당 연산을 통한 값은 Set of Arcs($A$)라는 공간에 저장되며, $\beta,\ \sigma, A$ 로 State $c$를 만들 수 있고, $c$를 input으로 하는 함수 $f(c)$를 통해 decision을 만들 수 있다. $ c = (\sigma, \beta, A$) BUPPER에서 STACK으로 움직이는 방향으로만 Shifting 된다.
단점
- Binary & Sparse representation
- Parsing 소요시간 중 95% 이상을 feature 연산이 차지 (계산비용이 높음)
- 단어 또는 POS Tag의 의미를 반영하지 못함
'Deep Learning > CS224N' 카테고리의 다른 글
| [CS224N] Machine Translation (MT), Attention (0) | 2021.09.03 |
|---|---|
| [CS224N] Language Model (n-gram, NNLM, RNN) (0) | 2021.09.01 |
| [CS224N] Named Entity Recognition(NER) (0) | 2021.08.31 |
| [CS224N] cound based Word Prediction model (GloVe) (0) | 2021.07.22 |
| [CS224N] SVD, Word2Vec를 통한 NLP (0) | 2021.07.20 |