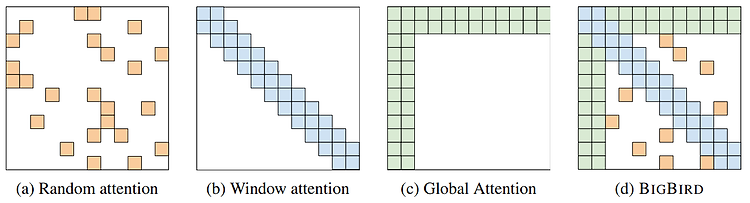
Contents RNN, LSTM, GRU 이후 Transformers가 제안되고 부터 다양한 분야에서 Transformer 기반 모델이 사용되었으며, 특히 자연어 처리(Natural Language Processing, NLP) 분야에서 많이 사용되고 있다. 이번 글에서는 Transformers의 문제를 개선한 모델인 Bigbird를 제안한 논문을 리뷰하고자 한다. [Transformers], [Bigbird] Introduction BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) 등과 같이 Transformer-based model(이하 Transformers)..