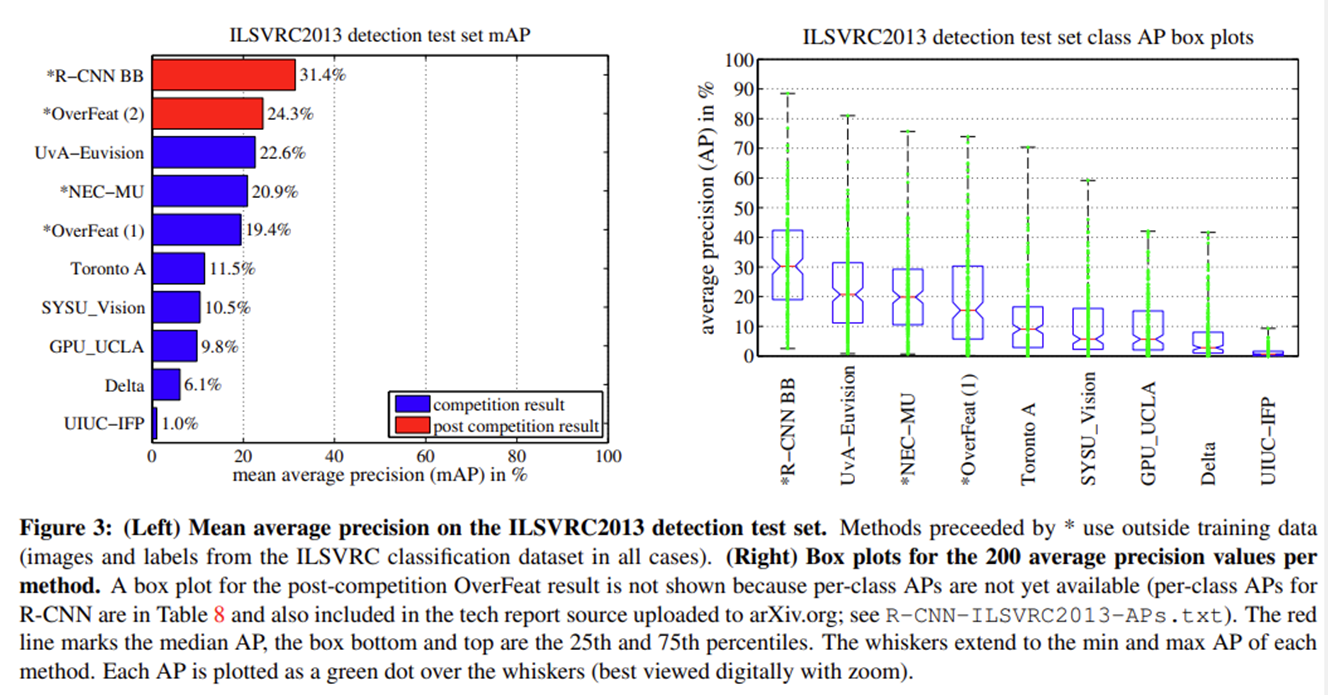
R-CNN을 제안한 논문인 Rich feature hierarchies for accurate object detection and semantic segmentation (2014) 에 대해 리뷰를 하고자 한다. R-CNN이 등장하기 이전에는 SIFT[논문], HOG[논문] 을 활용한 방법으로 Object Detection을 하고 있었으나 몇 년 간 성능 개선을 보이지 못하고 있었다. R-CNN은 기존 모델의 성능을 31.4% 만큼 개선함으로써 엄청난 성능을 보여주었다. (24.3% $\rightarrow$ 53.7%)
기존의 모델들은 물체가 있을 만한 곳을 하나씩 탐색하는 방법인 Sliding Window 을 사용해 물체를 탐지했는데, 이 방식은 크기가 고정되지 않아 여러 크기로도 순차적으로 탐색해야하기에 연산하는 양이 너무 많아 비효율적인 방법이다. 이와 달리 R-CNN은 Sliding Window 방식이 아닌 Region proposals을 제안하고 CNN을 결합해 엄청난 성능 개선을 보여주었다.
R-CNN algorithm
지난 몇 년간 다양한 visual recognition tasks에서는 SIFT, HOG와 같은 blockwise orientation histogrmas을 사용하였으나 이는 2010~2012년 사이에 PASCAL VOC datasets에 대해 아주 미비한 성능개선만을 보여주고 있었고, 이때 R-CNN 기법이 제안되었다. R-CNN은 VOC2010 기준 기존의 기법보다 31.4% 만큼의 성능 개선시키며 recognition 분야에 새로운 방향을 제시하였다.
R-CNN 알고리즘은 다음과 같이 구성되어 있다.
1. category-independent region proposals을 생성한다. (Region Proposals)
2. CNN을 사용해 각각의 region으로부터 고정된 길이의 feature vector를 추출한다. (Convolution layer)
3. SVM을 사용해 분류한다. (SVM Classifier)
Region Proposals
R-CNN은 Sliding window 방식을 사용하는 기존 방식과는 달리 다양한 category-independent method 중에서 selective search 방법을 사용하여 region proposal을 추출하는데, selective search는 아래와 같은 방법으로 진행된다.
- input image에 대해 각각의 개체가 한 개의 영역에 할당될 수 있도록 많은 초기 region 영역을 생성
- Greedy algorithm을 이용해 region을 기준으로 주변 유사한 영역을 결합
- 결합된 region을 최종 region proposal로 사용

2000개의 candidate region proposal을 생성하고 크기에 상관없이 이미지를 227x227로 warp(resize) 한다. 또한 성능 개선을 위해 물체 주변의 16 pixel까지 포함했다. Selective search를 사용해 생성한 2000개의 region proposal 중에서 겹치는 region을 제거하기 위해서 Non-Maximum Suppression을 사용하는데, 이는 Threshold를 설정해 region proposal을 같은 물체로 볼 것인지, 다른 물체로 볼 것인지 IoU를 기준으로 판단하는 방법이다.
Conv Layer
CNNs은 1990년대에 처음 제안되었지만, SVM의 등장으로 인해 유행에서 뒤쳐지게 되었으나 AlexNet의 등장으로 다시금 주목받게 되었다. 본 논문에서는 [논문]에서 제안한 사전학습된 AlexNet의 구조와 거의 유사하게 진행하며 각각의 region proposal 로부터 4096차원의 feature vector를 추출하였다. 총 5개의 Convolution Layer로 구성되어 있으며, Conv Layer의 경우 IoU가 0.5 이상이면 Positive, 미만이면 Negative로 분류한다.
이때 IoU는 0.5를 임계값으로 설정하여 IoU가 0.5 이상인 경우 positive로 설정하고, 0.5보다 작은 경우 negative로 간주한다.

SVM classifier
Convolution Layer에서는 IoU의 Threshold를 0.5로 설정했으나, SVM는 이와 달리 0부터 0.5까지로 설정한 후 성능이 가장 좋은 0.3으로 설정해 학습을 한다. AlexNet의 구조와는 다르게 Softmax가 아닌 SVM을 사용했는데 이는 SVM을 사용할 때 성능이 Softmax를 사용할 때 보다 3.3% 우수한 성능을 보여주었기 때문이다. 또한 Detection tasks에 적용하기 위해 마지막 출력을 200 혹은 20으로 변경해서 사용하였다.
Bounding Box Regression
R-CNN에서 처음에 2000개의 Candidate region proposal을 추출하게 되는데, 이는 랜덤으로 구성하기에 정확하게 물체를 인식할 수 있다고는 할 수 없다. 그렇기에 본 논문에서는 Bounding Box regression을 도입해 실제 Ground-truth와 생성한 Cndidate region proposal 간의 차이를 계산하여 차이를 줄이는 방법으로 학습하며 총 4가지의 절차를 따른다.
1. Convolution and Pooling 단계에서 pre-train 된 AlexNet을 이용해 Conv feature map을 생성한다.
2. box coordinates를 계산하기 위한 regression을 추가한다.
3. 훈련을 진행할 때 regression head 부분에 대해서만 SGD와 L2 loss를 적용해 모델을 학습한다.
4. test set에 입력할 때는 두 head 모두 사용하여 물체의 class와 coordinates를 예측한다.

우리는 하나의 bounding box $i$ 를 $P^i = (P^i_x, P^i_y, P^i_w, P^i_h) $로 표현할 수 있으며, 이와 같이 Ground-truth도 $Q^i = (Q^i_x, Q^i_y, Q^i_w, Q^i_h) $ 로 정의할 수 있다. $x,y$는 각 이미지의 중심점을 의미하고, $w,h$는 너비와 넓이를 의미한다. 이때 우리가 예측한 $\hat{G}$는 다음과 같다.
\[ \hat{G}_x = P_w d_x(P) + P_x \]
\[ \hat{G}_y = P_h d_y(P) + P_y \]
\[ \hat{G}_w = P_w \exp(d_w(P)) \]
\[ \hat{G}_h = P_w \exp(d_h(P)) \]
$x, y$는 하나의 점이기 때문에 크기에 상관없이 이동이 가능하지만, $w, h$는 이미지의 크기에 따라 비례하여 조정해주어야 하기 때문에 $\exp(d_*(P))$로 정의한다. 이때의 $d_*(P)$는 Ground-truth로 가기 위해 얼마만큼 Bbox를 움직여야 하는지에 대한 함수이며 우리가 찾아야할 함수다.

모델은 손실함수를 최소화하는 방향으로 학습하며, 본 논문에서는 손실함수를 아래와 같이 정의한다.
\[ \mathcal{L}_{reg} = \sum_i^N (t^i_* - \hat{W_*^T} \phi_5 (P^i))^2 + \lambda ||\hat{w}_*||^2_2 \]
이 손실함수를 최소화하는 $\hat{w}_*$를 찾는 것이 최종 목표라 할 수 있다.
\[ w_* = \text{argmin} \sum_i^N (t^i_* - \hat{W_*^T} \phi_5 (P^i))^2 + \lambda ||\hat{w}_*||^2_2 \]
이때의 $\phi$는 Convolution Layer를 거치고 마지막에 나온 Max Pooling Layer를 의미한다.
성능 비교
본 논문에서는 SVM classifier를 사용하는 R-CNN과 Bounding box regression을 사용하는 R-CNN BB를 ILSVRC2013 object dataset에 테스트 해보았는데, R-CNN BB의 성능이 훨씬 더 우수한 것을 확인하였다. (PASCAL VOC 데이터 셋에서도 동일하게 R-CNN BB의 성능이 우수하다.)

R-CNN은 사전학습된 AlexNet을 사용하여 적용하고자하는 Object dataset을 fine-tuning하는 방식으로 진행하는데, 표에 먼저 나온 3개의 모델은 사전학습하지 않은 모델을 사용한 것이고 아래 4개의 모델은 FT(Fine tuning)을 수행한 모델이다. 결과를 살펴보면 fine tuning을 할 경우 성능이 더 좋은 것을 확인할 수 있다.
문제점
하나의 이미지 당 2000개의 region을 생성하기 때문에 엄청난 양의 계산이 필요하게 된다. 따라서 속도가 늦다는 문제가 존재해 이후 Fast R-CNN, Faster R-CNN 등의 모델이 등장하게 된다.