Contents
Abstract
Referring Image Segmentation (RIS)는 입력으로 이미지의 영역의 Referring expression이 주어지면 Segmentation mask를 찾는 태스크다. RIS Task를 수행하기 위해서는 각 이미지 내 Segmentation에 대한 라벨이 지정된 데이터가 요구되는데 많은 비용과 인력이 투자된다.
본 논문에서는 이와 같은 문제를 해결하고자, 사전 학습된 CLIP을 기반으로 한 Zero-shot referring image segmentation method를 제안한다. 입력으로 주어진 텍스트 정보에서 segmentation mask 를 추출하기 위해, 입력된 이미지의 Global and local contextual information을 추출하는 Mask-guided visual encoder 방법을 제안하였다. 뿐만 아니라, 입력된 텍스트 정보에서 문장 수준의 정보(Global)와 명사구 수준의 정보(Local)를 추출할 수 있는 Global-local text encoder를 제안한다.
본 논문에서는 어떻게 이미지와 텍스트에 대한 Global, local contextual information을 추출할 수 있었는지에 초점을 두고 논문을 읽어나가면 된다.
Introduction
Computer Vision (CV), Natural Language Processing (NLP) 분야가 발전하면서, CLIP 등과 같은 Multi-modal 모델이 제안되고 있다. CLIP은 Object detection, Semantic segmentation 등과 같은 분야에서 많이 활용되고 있다. 그러나, Ojbect detection, Sementic segmentation 과 같은 분야에서 한 이미지 내에 많은 정보가 담겨있을 때에는 이를 예측하는 것이 다소 어렵다.
일부 연구에서는 이와 같은 문제를 해결하기 위해 fine-tuning을 수행하여 task-specific한 annotation을 수행하여 연구를 진행하고 있으나, 이는 직접 사람이 라벨링을 수행해야 하기 때문에 매우 노동 집약적(labor-intensive)이고 많은 비용이 요구된다.
Referring Image Segmentation (RIS) 는 초록에서도 간략하게 설명했지만, 특정 영역을 설명하는 텍스트를 바탕으로 이미지에서 어떤 영역인지를 찾는 Task를 나타낸다. RIS Task에서 Annotation 데이터를 수집하는 것은 매우 어려운 작업이다. 이와 같은 문제를 해결하기 위해 Weakly-supervised RIS 방법론도 제안되었으나, 여전히 Image-Text 정보가 많이 필요하다.
본 연구에서는 이와 같은 문제를 해결하고자, RIS Task에서의 CLIP 기반 Zero-shot Transfer에 초점을 맞추었다. RIS Task는 텍스트와 이미지의 일치하는 영역을 매핑시켜야 하기 때문에 텍스트와 이미지에 대한 고차원적인 이해가 있어야 한다.
Figure 1을 예시로 살펴보면, 오토바이 위에 고양이 2마리가 있다. 이때 "a cat is lying on the seat of the scooter" 라는 Text 정보를 주었을 때, Local-context 에서는 "cat"이 선택되어 2마리의 고양이가 선택될 것이다. Global-context 에서는 "lying on", "seat", "scooter" 라는 정보를 받아, 실제 고양이가 어디에 위치해 있는지를 파악하여 최종적으로 Global-Local Context를 고려하면 초록색으로 Segmantation된 고양이가 선택되는 것이다.

그러나, Zero-shot learning을 기반으로 한 연구에서는 서로 다른 특성 정보를 구별할 수 있는 능력이 부족하다. 본 연구에서는 Zero-shot learning에서 위 RIS Task를 수행하기 위해, Global, Local context 정보를 고려할 수 있는 새로운 방법론을 제안한다. 이를 위해 Mask-guided visual encoder와 Global-local textual encoder를 사용하였으며, Section 3에서 상세히 다뤄보자.
Method
Figure 2는 본 연구에서 제안하는 모델의 Overall framework를 나타낸다. Visual 정보를 추출하기 위한 Global-local visual eoncoder와 Referring expression 정보를 추출하기 위한 Global-local natural language encoder로 구성되어 있다. RIS 에서의 목적은 기본적으로, 텍스트와 이미지 간의 유사도를 계산하여야 한다. 즉, 아래와 같은 수식을 최대화하는 형태로 접근하는 것이다.
\[ \hat{m} = \text{arg} \underset{m \in M(I)}{\text{max}} \text{sim} (t, f_m)\]
$t$는 Global-local textual feature를 의미하고, $f$는 Mask-guided global-local visual feature를 의미한다. 이때, $M(I)$는 입력으로 주어진 이미지에 대한 Mask proposal set을 의미한다.

Mask-guided Global-local Visual Features
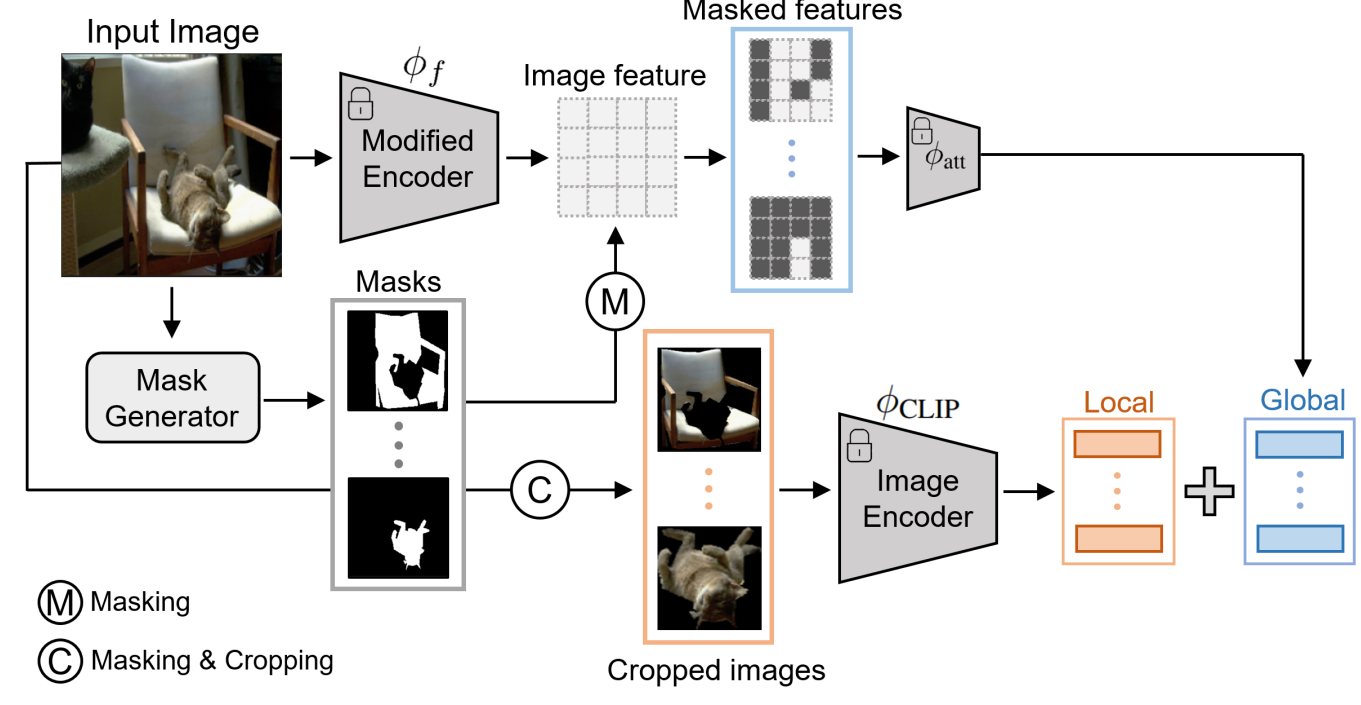
CLIP 모델은 Image-Level 에서의 표현을 학습하는 것으로 설계되어 있기 때문에, Pixel-Level 에서의 표현을 추출하기 위한 Task에 사용하는 것은 적합하지 않다. 본 연구에서는 이와 같은 문제를 해결하기 위해 Mask proposal generation과 Masked image-text maching으로 모델을 구성하였다. 먼저, Mask proposal을 생성하기 위해, 기존 연구에서 제안된 mask extractor를 사용하였다.
Global-context Visual Features
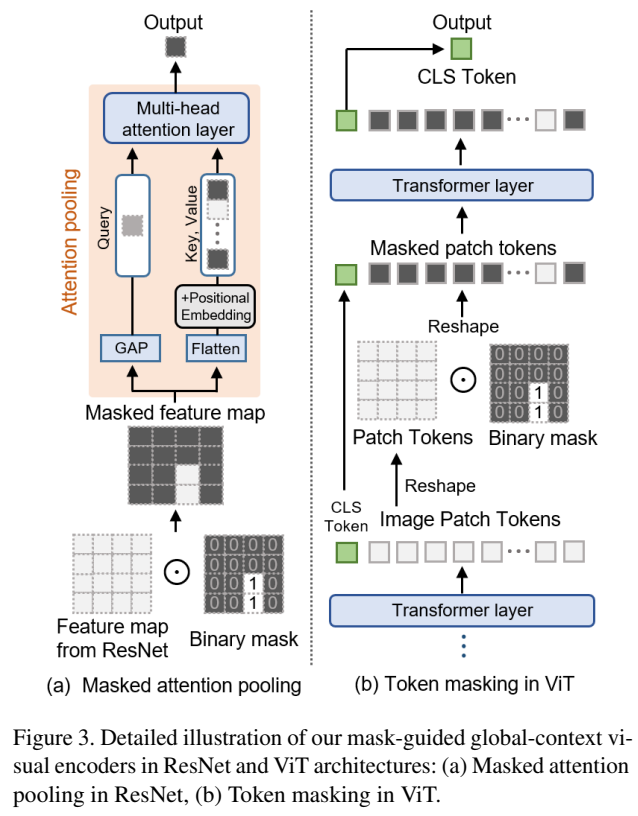
각각의 Mask proposal에 대해서 CLIP을 사용하여 Global-context Visual Feature를 추출하였다. 그러나, 위에서도 언급했듯, CLIP으로 생성도니 Visual Feature는 전체 이미지에 대한 Vector를 생성하도록 설계 되어 있다. 본 연구에서는 아래의 그림과 같이 입력된 이미지를 Modified Encoder를 사용하여 마스킹된 영역 뿐만 아니라, 주변 영역에 대한 정보까지 추출하였다. 본 연구에서는 CLIP에서 이미지 정보를 추출하기 위한 Backbone 모델로 ResNet, ViT를 사용하였으며, Implementation Detail Part에서 더 상세히 확인할 수 있다.
\[ f = \phi_{\text{CLIP}} (I) = \phi_{\text{att}} (\phi_{f} (I)) \]
\[ f^G_m = \phi_{\text{att}} (\phi_{f}(I) \odot \bar{m}) \]
Local-context Visual Features
Local-context visual feature를 추출하는 단계에서는 먼저, Cropped Image를 생성한 후, CLIP Layer를 통과시킨다. 이를 수식으로 표현하면 아래와 같다.
\[ f^L_m = \phi_{\text{CLIP}} ( \mathcal{T}_{\text{crop}} (I \odot m)) \]
$\mathcal{T}_{\text{crop}}$는 Cropping operation을 의미한다.
Global-local Context Visual Features
이전 단계에서 생성된 Global context feature와 Local context feature를 취합하는 단계며, 이때 $\alpha$를 기준으로 최종 Feature를 생성한다.
\[ f_m = \alpha f^G_m + (1-\alpha) f^L_m \]
이때, $\alpha \in [0, 1]$의 값을 가지는 상수를 의미하고, $m$는 Mask proposal, $f^G$, $f^L$는 각각 Global, Local feature를 의미한다.
Global-local Textual Features
Global-local Textual feature 를 추출하는 과정도 Visual Feature를 추출하는 것과 유사하게 Global과 Local을 분리하여 추출하였다. 먼저 Global textual feature을 추출하기 위해, 입력으로 Referring experssion $T$가 주어지면, 이를 CLIP에 입력으로 사용하여 아래와 같이 추출하였다.
\[ t^G = \psi_{\text{CLIP}} (T)\]
그 다음 단계는 Local textual feature를 추출하는 것이다. Local feature를 추출하기 위해서는 입력으로 주어진 문장 내에서 명사구(Noun Phrase)를 추출해야 한다. 이때, spaCy 패키지를 사용해서 명사구를 추출한 후 이를 모델의 입력으로 사용하였다.
\[ t^L = \psi_{\text{CLIP}} (NP(T))\]
이때 $NP$는 명사구를 추출하는 함수를 의미한다. 최종적으로 아래와 같은 수식을 통해 Global-local Textual Feature를 추출한다.
\[ t = \beta t^G + (1-\beta) t^L \]
Implementation Detail
본 연구에서는 CLIP의 Backbone 모델로 ResNet과 ViT를 사용하였다 [Figure 3 참조]. ResNet의 경우 Masked attention pooling 형태로 수행하였고, ViT의 경우 Token 자체를 Masking하는 형태로 입력을 처리하였다.
Experiments
실험에 사용된 데이터는 RefCOCO, RefCOCO+, RefCOCOg를 사용하였으며, 평가지표로는 oIoU (overall Intersection over Union)과 mIoU (mean Intersection over Union)을 사용하였다. oIoU의 경우는 총 면적에서 겹치는 면적을 나눈 값의 합산을 의미한다. 반면에, mIoU는 총 면적에서 겹치는 면적을 나눈 값에서 데이터의 수 만큼 나누어 평균을 취해준 값을 의미한다.
실험은 Main Results, Zero-shot Evaluation on Unseen Domain, Ablation Study (Effect of mask Quality, Effect of Global-Local Context Features, Qualitative Analysis) 로 총 3개의 파트로 나누어서 진행하였다.
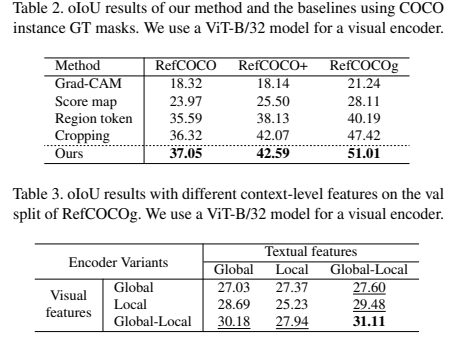
첫 번째, Main Results의 경우 기존 Zero-shot Baselines 모델과 비교했을 때의 성능을 비교 분석한 것이며, Table 1에서 확인할 수 있다.
두 번째, Zero-shot Evaluation on Unseen Domain의 경우 Figure 4에서 확인할 수 있다. k=32, 즉, 새로운 도메인에서 데이터를 32개 이하로 주어진 경우에는 본 연구에서 제안하는 모델의 성능이 우수한 것을 확인할 수 있고, 더 많은 데이터가 주어지게 되면, 기존 연구에서 제안된 Supervised learning의 성능이 우수한 것을 확인할 수 있다.

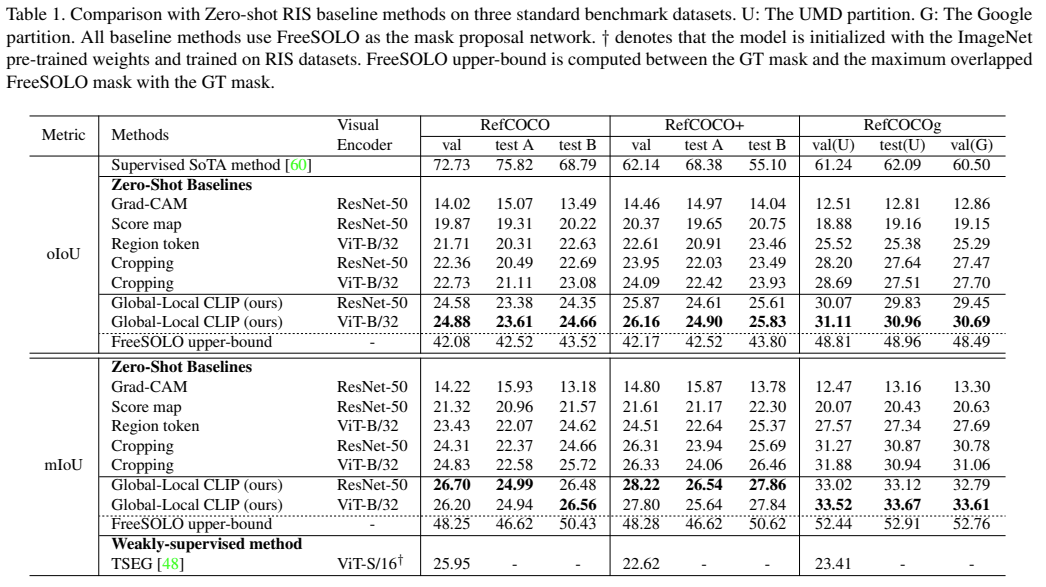
마지막 Ablation Study의 경우 Table 2 (Effect of Mask Quality), Table 3 (Effects of Global-Local Context Feature), Figure 5, 6 (Qualitative Analysis) 에서 확인할 수 있다. 본 연구에서 제안하는 방식의 Mask Quality가 더 우수한 것을 확인할 수 있다. Table 3을 확인하면, 이미지와 텍스트의 정보를 사용할 때 Local-Local < Local-Global < Global-Local < Global-Global 순서로 성능이 우수한 것을 확인할 수 있고, 이미지와 텍스트에 대해서 Globa-Local 정보를 모두 고려한 경우에 가장 우수한 성능을 보이는 것을 확인할 수 있다.