이 논문은 YOLO의 처음 제안한 v1 버전의 논문이다. 기존의 Object Detection 관련 논문 (R-CNN, Fast R-CNN, Faster R-CNN) 등의 논문들은 Region Proposal을 생성하고 Classification하는 두 개로 된 2 stage detection 방식을 사용했으나, YOLO의 경우 1 stage detection 방식을 사용해 이슈가 되었다. YOLO는 이름에서도 알 수 있듯 아래와 같은 장점이 존재한다.
1. You Only Look Once : 이미지를 한 번만 보고 처리를 한다.
2. Unified : Stage를 결합하여 One Stage detection을 수행한다.
3. Real-Time : 속도가 매우 빠르다.
Object Detection
ImageNet 대회에서 ResNet의 등장으로 오류가 3%대로 진입하자 단순한 이미지의 카테고리 분류가 아니라 물체가 어디에 위치하고 있는지까지 표시하는 Object Detection 분야가 관심을 끌기 시작했다. 단순히 이미지가 어떤 카테고리인지 하나만 분류하는 것이 아니라 이미지 내의 여러 물체를 전부 인식하기에 상당히 까다로운 작업이라 할 수 있다.
Object Detection은 물체가 있을법한 곳을 하나의 박스로 표시하고 카테고리를 분류하는 것이다. 아래의 그림에 보이는 것처럼 Bounding Box는 박스의 중심점 x,y 좌표와 너비 w, 높이 h로 총 4개의 값을 가지고 있다. 따라서 모델을 학습하고 난 후 출력되는 값은 x,y,w,h로 되어 있으며, Box로 표시한 물체의 클래스까지 함께 출력된다.

One Stage Detection
처음에도 언급했듯 YOLO는 One Stage Detection 방식을 사용한다고 했다. 기존의 모델들은 VGGnet, ResNet, AlexNet 등과 같이 사전 학습된 이미지 분류 모델을 기반으로 Region Proposal을 생성하고 이를 바탕으로 학습하는 방식으로 진행하고 있다. 반면에 YOLO는 이 과정을 한 번에 합쳐서 진행해 분당 처리 속도를 엄청나게 개선시켰다. (실시간 처리가 가능하도록)

One Stage Detection은 이미지를 입력으로 받고 Convolution Layer와 Fully Connected Layer를 거친 후 reshape과정을 수행해 Tensor 형태의 Output을 출력한다. 이후 어떠한 알고리즘을 수행해 이 이미지의 Bbox 정보와 Class 정보를 출력하게 된다. 아래의 서베이 논문을 확인하면 모델의 발전 과정을 확인할 수 있다.
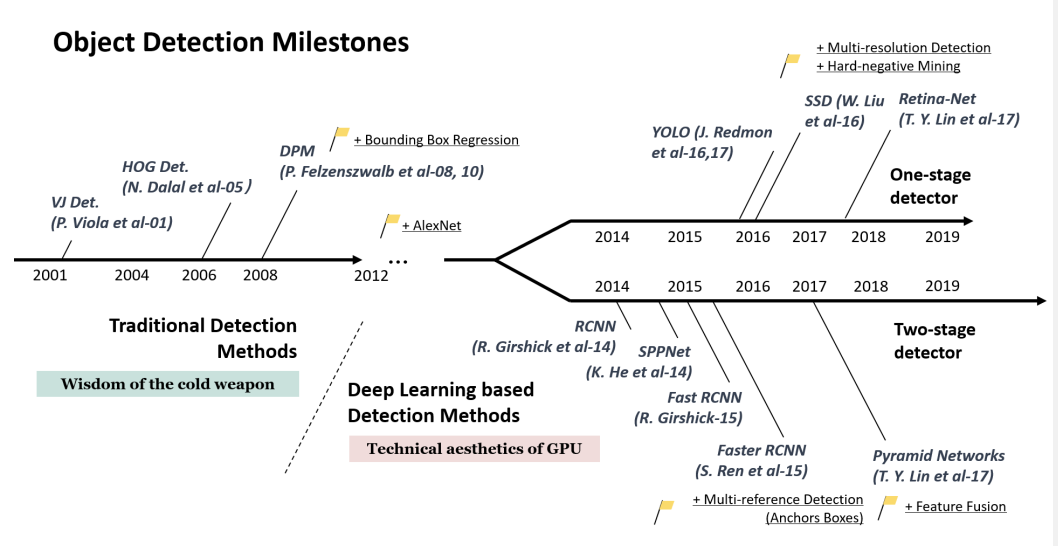
YOLO는 region proposal, feature extraction, classification, bbox regression을 하나의 one stage detection으로 결합했다고 언급했다. 그렇다면 어떤 식으로 결합을 했을까? 먼저 이미지를 입력받으면 입력받은 이미지 전체를 대상으로 얻은 feature map을 활용하여 bbox 예측과 모든 클래스에 대한 확률을 계산하게 된다.
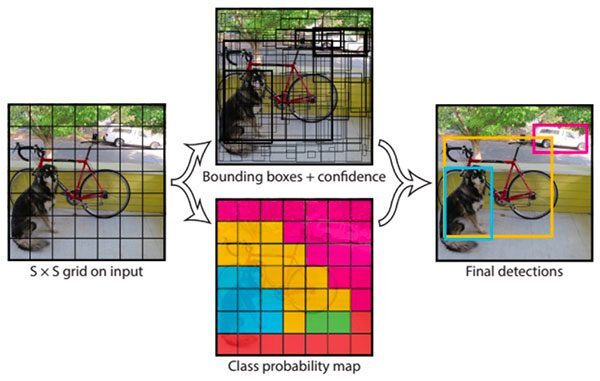
입력받은 이미지는 SxS grid로 분할하고 Bounding regression을 하는 stage와 각 grid cell마다 class probability map을 계산하는 stage로 보내 병렬적으로 수행하고 있다. 본 논문에서는 7x7로 나누어 이미지를 49개의 cell로 분할했다.

S=7, B=2, C=20 이라고 가정하면 grid cell 하나당 bounding box를 두개씩 그리고 하나의 바운딩 박스는 x,y,h,w와 박스 내 물체가 있을 확률인 Confidence score까지 해서 총 5개의 ouptut을 출력하게 된다. 이때의 w와 h는 Bbox의 w와 h가 아니라 전체 이미지에 대해서 normalize한 값이기 때문에 h/H, w/W로 표기하는 것이 옳다. B=2로 설정했기 때문에 빨간색 Bbox와 초록색 Bbox를 생성하기 때문에 총 10개의 output이 나오게 된다. 마지막으로 grid cell 내의 물체가 어떤 카테고리에 속하는지 확률값을 나타내는 Class probability map을 출력하고 output을 모두 결합하면 (2*5 + 20)의 output이 출력된다.
아래의 그림과 같이 grid cell 하나당 2*5 + 20 로 구성된 output이 7x7개 있으니 이를 결합해 7x7x30 차원을 가지는 Tensor가 출력된다.

YOLO Architecture
YOLO는 GoogLeNet의 구조를 가지고 와서 사용하였다. 1 by 1 Reduction layer를 사용하여 parameter 수를 줄여 모델이 잘 학습되도록 하였다.
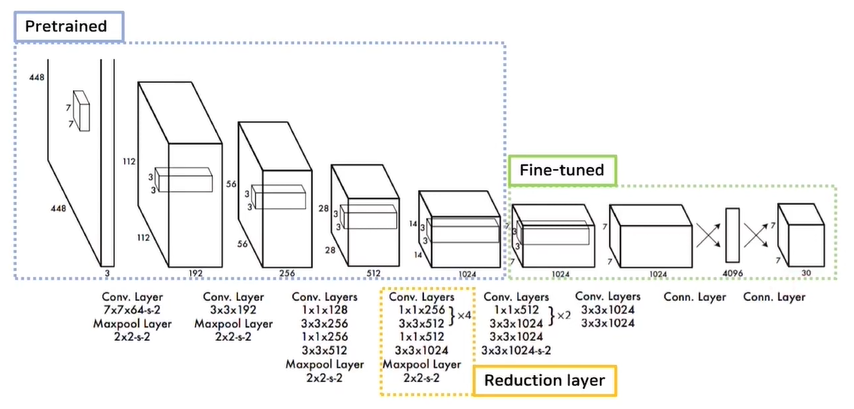
Train YOLO
이전까지는 YOLO에서 어떻게 One Stage Detection을 수행했는지에 초점을 맞추어 기술하였다. 지금부터는 어떤 방식으로 YOLO가 학습되는지를 다루어볼 것이다. 특정 Object에 대해 Groundtruth를 설정하고 Groundtruth의 중심이 위치한 부분의 grid cell을 Responsible한 cell으로 선정한다.
모델이 예측한 bbox는 엄청나게 많을텐데, 이때 IoU를 기준으로 IoU가 가장 높은 box를 최종 예측한 bbox로 선정한다. 그 후 실제 값 간의 차이를 계산해 이를 최소화하는 방향으로 진행한다.
Object Function
$\mathbb{1}^{\text{obj}}_{ij}$는 1번째 grid cell의 j번째 bbox가 객체 하나를 책임지고 있는지를 나타낸다. 만약 cell이 responsible한 셀이라면 1, 그렇지 않다면 0으로 표기한다. $\lambda_{\text{coord}}$는 localization의 비중을 늘리기 위한 값이며 본 논문에서는 5로 설정했다. $\lambda_{\text{noobj}}$는 no object의 class probability loss의 반영을 낮춘다는 것이며 본 논문에서는 0.5로 설정했다. 객체가 없는 부분의 비중을 낮추기 위함이다.

Loss Function은 grid cell에 object가 존재하는 경우의 오차와 predictor box로 선정된 경우의 오차만을 학습해 모델을 최적화하고 있다.
본 논문에서는 7x7 grid cell을 추출해 이미지 하나당 49개의 cell이 존재하고, 추가로 cell 하나당 2개의 Bbox를 출력하기 때문에 이미지 하나당 98개의 Bbox가 생성된다. 만약 이미지의 수가 많아진다면 Bbox가 엄청나게 많아지게 되고 이를 제한하기 위해 NMS(Non-Maximum Suppression) 라는 기법을 적용한다.
NMS는 R-CNN에서도 사용되는 기법 중 하나로 각 object에 대해 예측한 여러 bbox 중에서 가장 예측력이 좋은 bbox만을 남기는 기법이라고 이해하면 된다. 이는 grid cell에다가 적용하는 것이 아니라 각각의 클래스에 대해 적용하는 것이다.



그러나 한 그림에 다른 그림이 있을 경우에는 어떻게 진행할까? 클래스에서 가장 높은 Bbox를 선택하는 NMS를 적용하면 가장 IoU가 높은 추출하게 되면 하나만 추출한다고 생각할 수 있는데, 아래와 같은 방식으로 확률값이 높은 다른 친구도 추출하기 때문에 다른 곳에 있는 물체도 추출할 수 있다.

Experiment Result
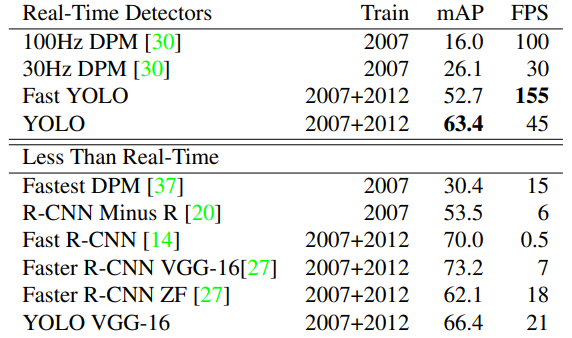
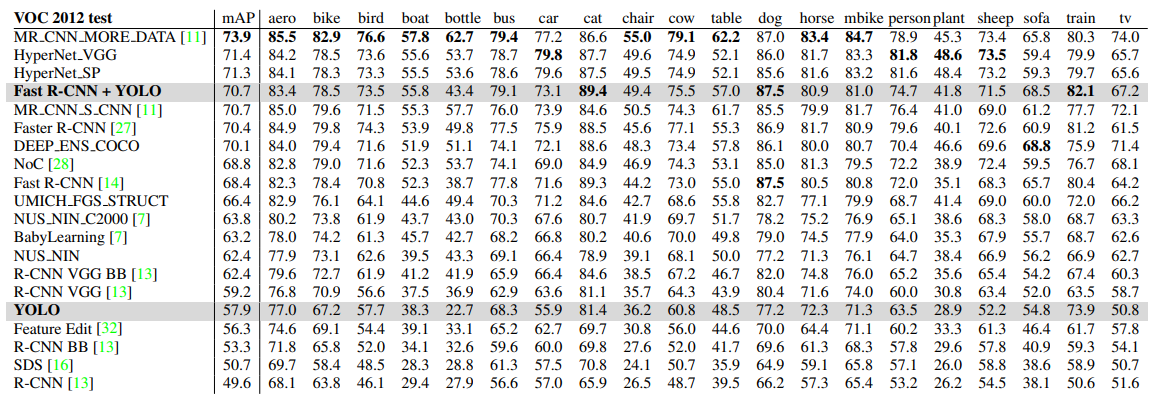
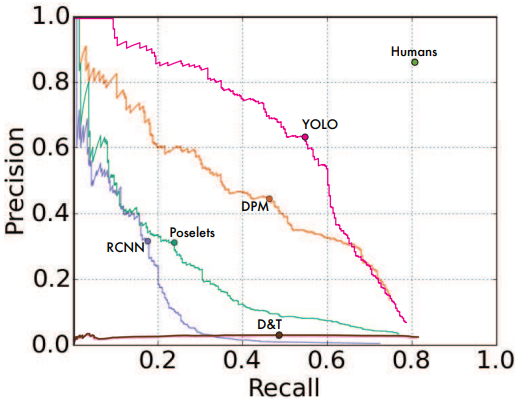
본 논문에서는 PASCAL VOC 2007 데이터를 기반으로 모델을 학습하여 이전에 나온 모델들과의 성능을 비교하였다. FPS(속도)의 경우 Fast YOLO가 가장 높은 것을 의미한다. 일반적으로 동영상이 1초에 30 프레임을 다루고 있으니, 30보다 높은 경우에 실시간으로 처리가 가능하다. 따라서 YOLO는 실시간으로 처리가 가능한 모델이라고 할 수 있다.
Fast R-CNN에 비해 Background error가 현저히 줄어든 것을 확인할 수 있다. Background error는 Background에 물체가 없는데 있다고 판단하는 것을 의미한다. 또 한가지 특이한 점은 Fast R-CNN과 YOLO를 결합했을 때 mAP가 3.2% 향상된 것을 보여준다.


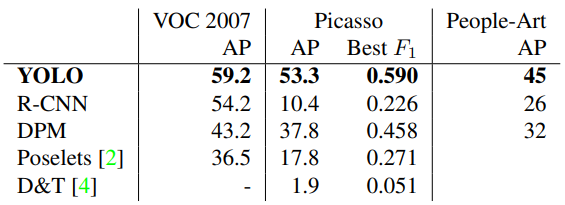
아래의 그림은 YOLO가 사진 뿐만 아니라 그림에 대해 물체를 인식한 결과를 보여주는데, 피카소 그림과 사람의 그림에 대해서도 엄청난 성능을 보여주는 것을 확인할 수 있다.

Limitations
본 논문에서 언급하는 YOLO의 한계는 다음과 같다.
1. 하나의 grid cell에 두 가지의 물체가 존재한다면 이는 제대로 구분할 수가 없다.
2. 데이터로부터 Bbox 예측을 학습하기 때문에 학습데이터에 없던 종횡비는 대처가 어렵다.
3. 바운딩 박스의 크기와는 상관없이 동일한 loss를 주기 때문에 성능에 악영향을 미칠 수 있다.
object가 크면 Bbox 간의 IoU 값의 차이가 커져서 적절한 predictor를 선택할 수 있지만, object가 작으면 bbox 간의 IoU 값의 차이가 작아서 매우 작은 차이가 존재하는 predictor를 선택하기 때문이다.



