본 논문은 NIPS'22 에서 발표된 논문이며, 이름에서도 알 수 있듯, Perturbation을 통해 Anomaly Detection을 수행하는 PLAD (Perturbation Learning Anomaly Detection) 기법을 제안한다. 여기서 Perturbation은 아주 작은 노이즈를 의미하며, 정상(Normal) 데이터에 작은 노이즈를 집어 넣어 성능을 개선한다는 내용이다. 이때 정상 데이터에 너무 심한 노이즈를 집어넣을 경우 오히려 성능이 저하될 수 있기 때문에 Perturbator를 제대로 구축하는 것이 핵심이며, 이 논문에서는 어떤 방식으로 수행하였는지 알아보자.
$\mathbb{X} = {x_1, x_2, \cdots, x_n}$를 학습 데이터라고 표현하면, 학습 데이터로 $f(x) > 0 x \in \mathcal{D}$, $f(x) < 0 x \notin \mathcal{D}$를 잘 구별할 수 있는 Discriminative Function $f$를 학습하는 것이다. 이 때 $\mathcal{D}$는 정상 데이터의 분포를 의미하며, 정상 데이터의 분포를 벗어나는 값을 비정상(Abnormal) 데이터라 표현한다.
본 논문에서는 one-class SVM, deep SVDD, DROCC 등과 같은 이상치 탐지 모델과는 달리 정상 데이터의 분포 $\mathcal{D}$를 별도로 정의하지 않는다. 본 논문에서는 GAN 기법과 같은 방식으로 가짜 데이터 즉, 노이즈가 섞인 데이터를 이용하여 아래와 같은 목적 함수를 달성하는 형태로 학습한다.
\[ \underset{\theta, \tilde{\mathbb{X}}}{\text{minimize}} \frac{1}{n} \sum^n_{i=1} \mathcal{l} (y_i, f_{\theta} (x_i)) + \frac{1}{n} \sum^n_{i=1} \mathcal{l} ( \tilde{y}_i, f_{\theta} (\tilde{x}_i ) )+ \frac{\lambda}{n} \sum^n_{i=1} \phi (x_i, \tilde{x}_i ) \]
그러나 위와 같은 방식을 사용하게 되면, n의 수가 매우 많기 때문에 최적화하는 것이 어렵고, mini-batch 방식으로 구련하는 것이 어렵다. 또한, $\phi$는 정상 데이터의 분포가 사전에 정의되지 않았기 때문에 학습하는 것이 매우 어렵다. 본 연구에서는 위 3가지 문제점을 해결하고자, 아래와 같은 방법을 제안하였다.
\[ \underset{\theta, \tilde{\theta}}{\text{minimize}} \frac{1}{n} \sum^n_{i=1} \mathcal{l} (y_i, f_{\theta} (x_i)) + \frac{1}{n} \sum^n_{i=1} \mathcal{l} (\tilde{y}_i, f_{\theta} (\tilde{x}_i)) + \frac{\lambda}{n} \sum^n_{i=1} ( || \alpha_i - 1||^2 + || \beta_i - 0||^2 ) \]
\[ \text{subject to } \tilde{x}_i = x_i \odot \alpha_i + \beta_i, \quad (\alpha_i, \beta_i ) = g_{\tilde{\theta}} (x_i), \quad i = 1, 2, \cdots, n \]
여기서 $\alpha, \beta$는 Perturbator에 의해 생성되며, 이를 Perturbator에 대한 수식으로 변환하면 아래와 같다.
\[ \underset{\theta, \tilde{\theta}}{\text{minimize}} \frac{1}{n} \sum^n_{i=1} \left ( \mathcal{l} (y_i, f_{\theta} (x_i) ) + \mathcal{l} (\tilde{y}_i, f_{\theta} (x_i \odot g^{\alpha}_{\tilde{\theta}} (x_i) + g^{\beta}_{\tilde{\theta}} (x_i) ) ) \right) \]
\[ + \frac{\lambda}{n} \sum^n_{i=1} \left ( ||g^{\alpha}_{\tilde{\theta}} (x_i) - 1 ||^2 + || g^{\beta}_{\tilde{\theta}} (x_i) - 0 ||^2 \right ) \]

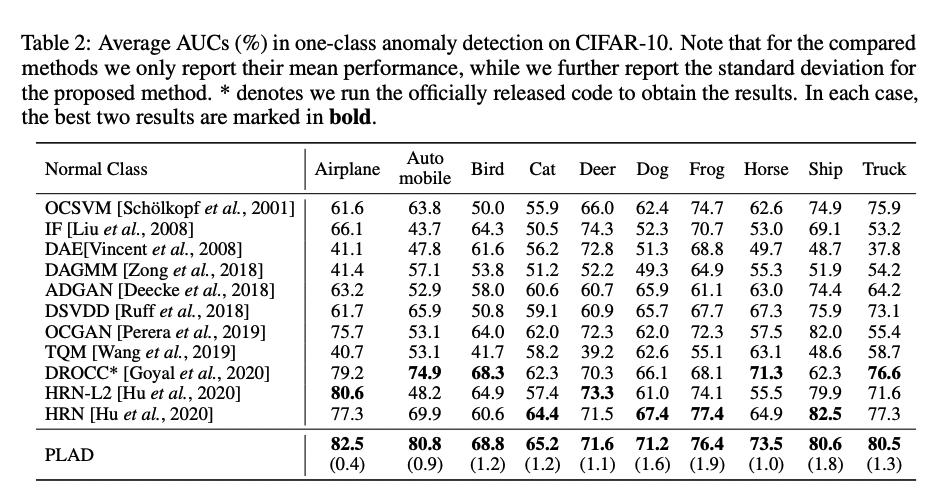
본 연구에서는 성능을 비교하기 위해 이미지 데이터와 정형 데이터를 바탕으로 실험을 진행하였고, 실험 결과 CIFAR-10, Fashion-MNIST 데이터 셋에서 나름 우수한 성능을 보이는 것을 확인할 수 있다.