Contents
Introduction
해당 논문은 CVPR'22에서 발표된 논문으로 Reverse Distillation을 통한 이상 탐지 모델을 제안하고 있다. 이때 Distillation은 Knowledge Distillation에서 나온 개념으로, 사전 학습된 모델을 바탕으로 Teacher와 Student를 구성하고 이를 이용해 이상 탐지를 하는 방식이다. 기존 Distillation 모델의 경우 Teacher Encoder와 Student Encoder를 구성해 Teacher의 출력값과 Student의 출력값을 비교하여 모델을 재학습 한다. 학습 단계에서 Student 모델은 정상 데이터만을 바탕으로 학습하는데, 정상 데이터만 학습하게 되면 Student는 정상 데이터를 잘 분류할 수 있는 구별 기준을 만들게 된다. 그런 다음, Inference 단계에서 이상치가 입력으로 들어왔을 때, Teacher의 출력값과 Student의 출력값을 비교해서 이상치인지 아닌지 분류하는 방식이다. 그러나, Teacher와 Student 모델의 구조가 같거나 유사하고, 같은 Data Flow를 가지고 있기 때문에 이상치를 잘 구분할 수 없다는 문제가 존재한다.
따라서, 본 논문에서는 Reverse Distillation라는 개념을 도입하여 이미지를 바로 Student 모델에 입력하는 것이 아니라, Teacher의 출력값을 바탕으로 Student를 이용해 복원하는 형태로 구성되어 있다. (Figure 2 참조) 이처럼 Reverse Distillation을 사용하게 되면 두 가지의 장점이 존재한다. 첫 번째 장점은 Teacher와 Student가 서로 유사하지 않은 구조를 가진다(Non-Similarity). Teacher Encoder는 down-sampling을 수행하게 될 것이고, Student Encoder는 up-sampling의 구조를 가지기 때문이다. 또 하나의 장점은 Low-dimensional Embedding (Teacher Output)이 Student의 입력으로 들어가서 비정상적인 Perturbation의 영향을 줄인다(Compact Embedding). 이렇게 되면, 비정상 이미지가 들어왔을 때 Teacher와 Student의 출력값이 기존 Distillation 모델보다 커진다.
지금까지 구조를 살펴보면 AutoEncoder와 다른 점이 무엇인가? 라고 생각할 수 있다. 본 논문에서 언급하는 AutoEncoder와의 차이는 바로, Pixel Difference와 Dense Descriptive Feature의 차이라고 한다. AutoEncodersms Pixel Difference로 픽셀 간의 차이를 통해 이상치를 탐지한다면, Reverse Distillation은 Dense Descriptive Feature를 통해 이상치를 탐지한다. Dense Descriptive Feature를 사용하게 되면 보다 효과적으로 식별 정보를 제공한다고 한다.
그 뿐만 아니라 본 논문에서는 학습 가능한 One-Class Bottlenect Embedding (OCBE) 기법도 추가로 사용한다. OCBE 기법은 Figure 2(b)에서 초록색에 해당하는 부분이다. 위에서 언급한 것 처럼 Dens Descriptive Feature를 사용하여 이상치를 탐지하는 것이기 때문에 해당 영역 정보를 더 압축하여 사용하기 위해 OCBE 기법을 사용하는 것이다. OCBE 기법은 Multi-Scale Feature Fusion (MFF)와 One-Class Embedding (OCE)로 구성되어 있다. MFF는 정상 패턴을 학습하기 위한 모듈이고, OCE는 Student 모델이 Teacher 결과값을 구분하기에 유리한 정보를 유지하는 것을 목적으로 하는 모듈이다.

Reverse Distillation
Problem Formulation: $\mathcal{I}^t = \{I^t_1, \cdots, I^t_n \}$를 Anomaly-free한 이미지 집합이라 하고, $\mathcal{I}^q = \{I^q_1, \cdots, I^q_m \}$는 정상과 비정상으로 구성된 쿼리(Query) 집합이라고 하자. 최종 목적은 쿼리 집합 내에 있는 데이터에서 비정상 이미지를 인식하기 위한 모델을 학습하는 것이다. 이때, $\mathcal{I}^t$와 $\mathcal{I}^q$는 같은 분포를 따르고, Out-of-Distribution에 해당하는 이미지는 이상치로 분류한다.
전통적인 Knowledge Distillation 모델은 Student 모델을 Teacher 모델과 유사하거나 같은 모델로 사용한다. 이때 학습되지 않은 이상치에 대한 One-Class distillation 맥락에서 Student 모델은 Teacher와 매우 다른 표현을 생성한다는 것을 가정으로 한다. 그러나, 가끔씩 이상치와 차이가 감소하는, 즉, 이상치라고 분류하지 못하는 경우가 발생하는데, 본 논문에서는 이를 해결하고자 다른 Data Flow를 가지는 구조인 Reverse Distillation 방법을 제안하였다.
실제 Student를 학습할 때에는 Teacher $E$의 모든 파라미터를 Frozen 시키고 학습을 진행한다. 이와 같이 Frozen 시키지 않는다면, Teacher-Student 모델이 Trivial-Solution으로 수렴해버릴 수 있기 때문이다. 이때 $E$는 Ablation Study에서 실험한 결과, ResNet과 WideResNet의 성능이 가장 우수한 것으로 확인되어 이를 사용하였다(Kernel size = 1, Stride = 2). 그 다음으로는 MFF를 수행한다. MFF는 Multi-Scale Feature Fusion으로 Low-level Information (e.g., color, edge, texture)와 High-Level Information (regional/global semantic and structural information)를 각각 고려할 수 있다.
\[ f^k_E = E^k(I), f^k_D = D^k (\phi) \]
$I$는 Raw Data를 의미하고, $\phi$는 $I$를 입력으로 받아 Bottlenect Embedding Space로 Projection 시키는 함수를 나타낸다. 이때 $E^k$와 $D^k$는 각각 $k$번째 Encoding, Decoding Block을 의미한다($f^k_E, f^k_D \in \mathbb{R}^{C_k \times H_k \times W_k}$). 본 연구에서는 기존 선행 연구와 마찬가지로 KD Loss로 코사인 유사도를 사용하였다.
\[ M^k(h, w) = 1 - \frac{(f^k_E(h, w))^T \cdot f^k_D (h, w) }{ ||f^k_E(h, w) || \cdot || f^k_D(h,w) || } \]
이때 $M^k(h, w)$는 Channel axis를 기준으로 진행하기 때문에 $M^k \in \mathbb{R}^{H_k \times W_k}$가 된다. 그 다음으로, Student 모델을 최적화하기 위한 목적 함수를 다음과 같이 Multi-Scale을 고려하기 위한 Scalar Loss function을 정의한다.
\[ \mathcal{L}_{\mathcal{KD}} = \sum^K_{k=1} \left \{ \frac{1}{H_k W_k} \sum^{H_k}_{h=1} \sum^{W_k}_{w=1} M^k (h, w) ) \right \} \]

One-Class Bottlenect Embedding
앞에서 대부분의 구조를 다 설명했기 때문에 OCBE 구조는 매우 간단하게 설명할 수 있다. OCBE는 MFF 모듈과 OCE 모듈로 구성되어 있다. 먼저, MFF 모듈은 Multi-Scale을 고려하기 위해 Low-Level Information, High-Level Information의 정보를 가져온 다음에, Feature Shape을 맞추기 위해 아래와 같이 Teacher Encoder의 첫 번째 구조에서 CNN Block을 2 층, 두 번째 구조에서 CNN Block을 1층 쌓는다. 그런 다음 CNN Block마저 쌓고 나온 출력값을 OCE 모듈의 입력으로 사용한다. OCE 모듈에서는 MFF 모듈에서 얻은 정보를 콤팩트하게 압축하여 $\phi$로 압축한다. 그림에 나오는 ResBlock은 ResNet의 4번째 Residule Block을 사용하였다.

Anomaly Scoring
본 논문에서는 AutoEncoder와 다른 부분이 Anomaly Scoring이라고 했다. AutoEncoder에서는 픽셀을 기준으로 이상치를 탐지하지만, 본 연구에서는 $M$ 즉, Teacher Encoder와 Student Encoder의 각 Layer 별 Compact Representation을 사용하여 Anomaly를 탐지한다.
\[ S_{AL} = \sum^L_{i=1} \psi (M^i) \]
노이즈를 제거하기 위해 Gaussian Filter를 사용하였다.
Experiments
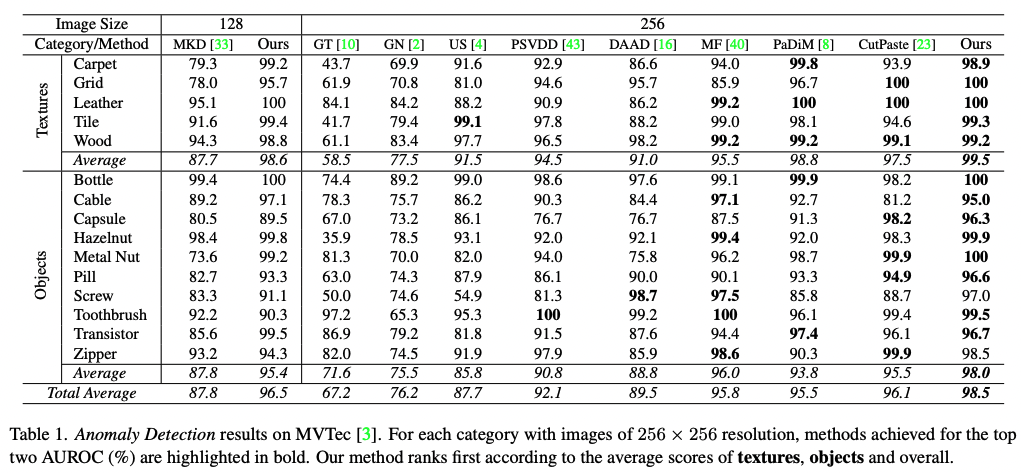
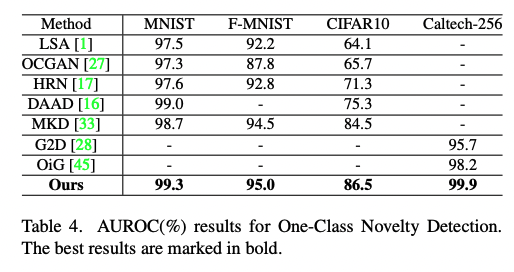
실험은 Anomaly Detection과 Localization을 수행하기 위한 데이터셋, 실험 환경 설정(Experiment Settings), 복잡도 분석(Complex Analysis), 한계점(Limitation), One-Class Novelty Detection, 제거 분석(Ablation Analysis), 그리고 결론으로 구성되어 있다. 본 연구에서 제안하는 Reverse Distillation 기법이 기존 연구에서 우수한 성능을 발휘하는 SPADE, PaDiM 등의 기법보다 속도도 더 빠르고 성능도 우수한 것을 보여주었다.