Contents
본 논문은 이상치 탐지(Anomaly Detection)를 위해 Prior Association과 Series Association 간의 차이 즉, Association Discrepancy를 이용한 Transformer 기반 모델 Anomaly Transformer를 제안하였다. 최적화를 위해 Minimax 방식을 사용하였으며, 기존 이상치 탐지 기법에 비해 월등히 높은 성능을 보이는 것을 확인하였다.
Introduction
이상치 탐지는 지도 학습(Supervised-Learning) 기반, 비지도 학습(Unsupervised-Learning) 기반 등 다양한 기법으로 구성되어 있다. 본 연구에서는 비지도 학습 기반 중 Transformer 기법을 활용하여 이상치 탐지를 수행한다. 학습 데이터가 주어지면 해당 데이터에는 이상치가 없다는 것을 가정하고 이를 학습하기 때문에 학습 데이터에 이상치가 존재하면 성능이 저하되는 문제가 발생한다. 이와 같은 문제를 해결하고자, Prior Association, Series Association이라는 개념을 도입하였다. 기본적으로 이상치는 단순히 특정 시점에 종속적인 것이 아니라 주변 값에 영향을 받는다. 이와 같은 이상치의 패턴을 파악하기 위해 Prior Association을 사용하고, 데이터 전체에 대한 정보를 파악하기 위해 Series Association을 도입하였다. 추가적으로 minimax 방식을 사용해 Prior Association과 Series Association을 학습함으로써 단순히 min, max를 사용하는 것 보다 성능을 향상시켰다.
Methods
Anomaly Transformer는 Prior Association, Series Association, Association Discrepancy으로 구성되어 있다. 먼저, Prior Association의 수식은 아래와 같다.
\[ \text{Rescale} \left ( \left [ \frac{1}{\sqrt{2 \pi} \sigma } \exp \left ( \frac{|j - i|^2}{2 \sigma^2} \right ) \right ] _{i, j \in \{ 1, \cdots, N \} } \right ) \]
Prior Association은 가우시안 분포를 활용하고 있는데, 이는 더 가까운 시점에 대해서 더 많은 가중치를 부여하기 위함이다. 또한, 고정된 평균값과 표준편차를 사용하지 않고, 학습 가능하도록 하여 성능을 향상시킬 수 있다.
다음으로 Series Association은 시계열 데이터 전체에 대한 정보를 고려하여 정상과 비정상을 구분할 수 있는 기준을 잡을 수 있으며, 아래와 같은 수식으로 표현할 수 있다.
\[ \text{Softmax} \left ( \frac{\mathcal{QK}^{\top}}{ \sqrt{d_{\text{model}} }} \right ) \]
Association Discrepancy는 Prior Association과 Series Association 간의 차이를 학습하기 위해 사용되는 방식으로, Series Association은 고정해두고 값을 최소화하는 방식을 사용하여 Prior Association이 Temporal Pattern을 학습하도록 만드는 Minimize Discrepancy와 Prior Association은 고정해두고 값을 최대화하는 방식을 사용하여 Prior, Series 간의 차이를 최대화하여 정상과 비정상을 구분할 수 있는 기준을 확립하기 위한 Maximize Discrepancy로 구성되어 있다.
\[ \text{AssDis}(P, S; X) = \left [ \frac{1}{L} \sum^L_{l = 1} ( KL (P^l_{i, :} || S^l_{i, :}) + KL(S^l_{i, :} || P^l_{i, :}) ) \right ]_{i=1, \cdots, N} \]
\[ \mathcal{L}_{Total} (\hat{X}, P, S, \lambda ; X) = ||X - \hat{X}||^2_F - \lambda \times || \text{AssDis} (P, S; X) ||_1 \]
\[ \text{Minimize Phase}: \mathcal{L}_{Total} ( \hat{X}, P, S_{detach}, -\lambda ; X) \]
\[ \text{Maximize Phase}: \mathcal{L}_{Total} ( \hat{X}, P_{detach}, S, \lambda; X) \]
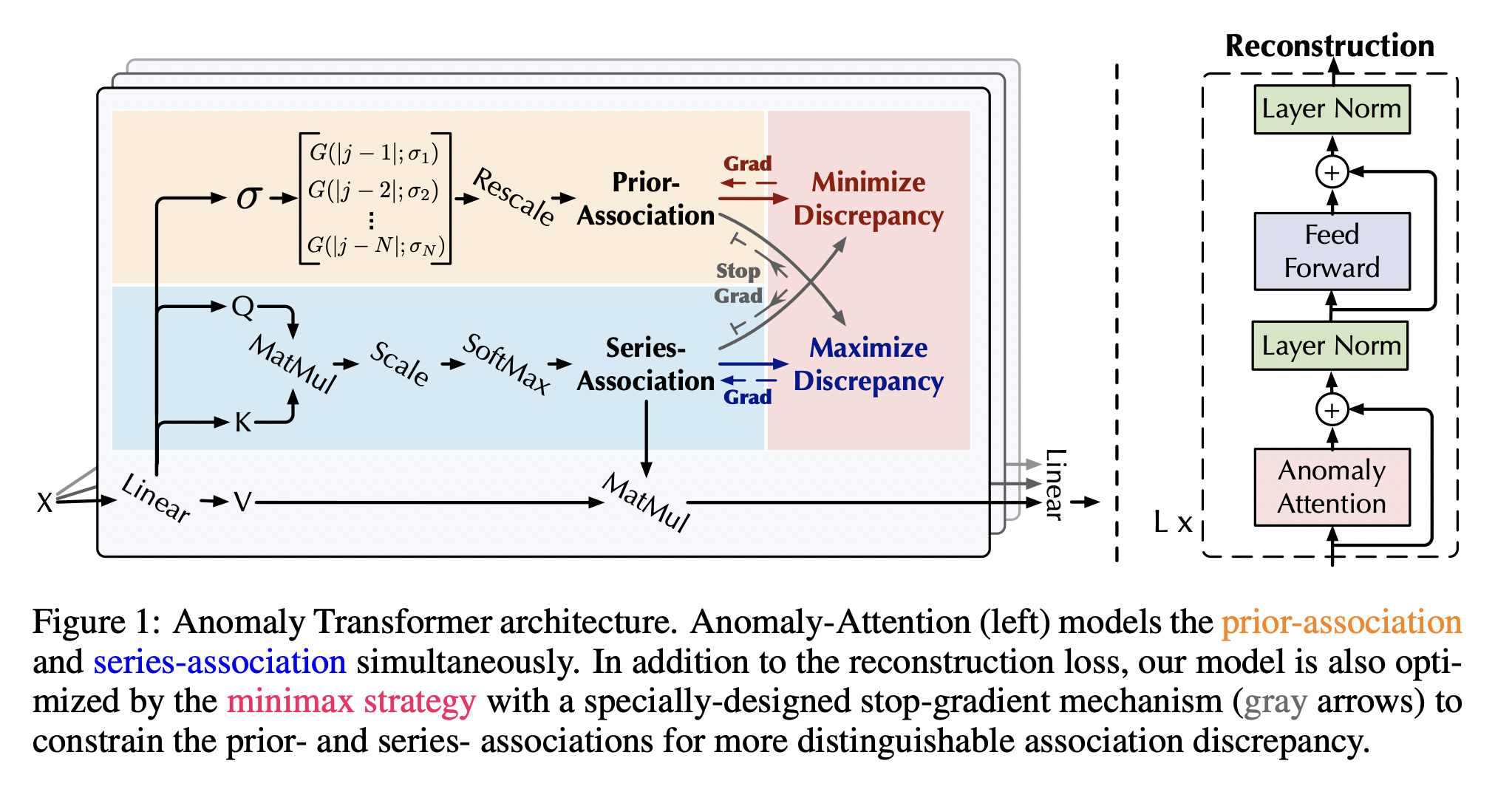
그다음으로, 해당 데이터가 이상치인지 아닌지를 구분하기 위해 Association based Anomaly Criterion을 아래와 같이 정의한다.
\[ \text{AnomalyScore}(X) = \text{Softmax} ( - \text{AssDis} (P, S;X) ) \odot \left [ || X_{i, :} - \hat{X}_{i, :}||^2_2 \right ]_{i=1, \cdots, N} \]
Experiments
실험은 베이스라인 모델과의 성능 비교, Ablation Study, Model Analysis로 구성되어 있다.
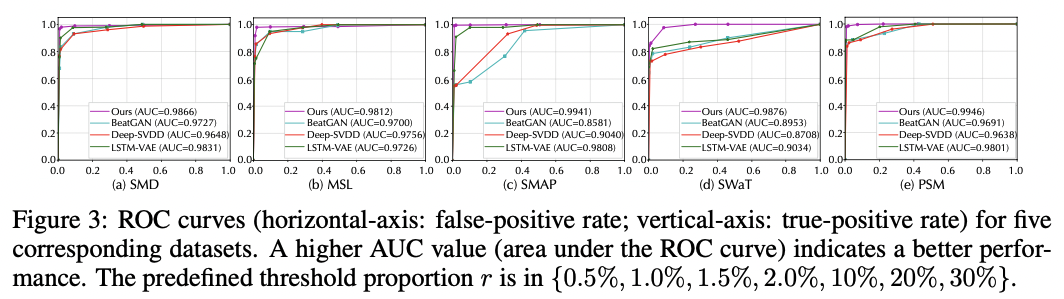
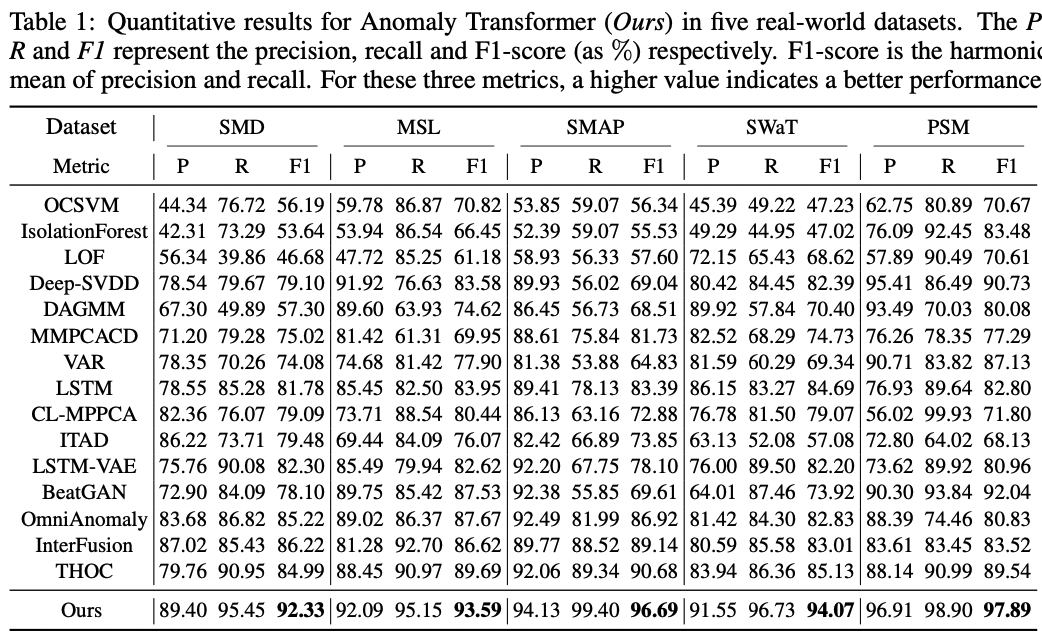
본 연구에서 제안하는 Anomaly Transformer의 성능이 다른 기법에 비해 월등히 우수한 성능을 보이는 것을 확인할 수 있다. 그 다음으로는 Ablation Study다. 본 연구에서는 Anomaly Criterion에서는 Reconstruction Loss와 Association Discripancy Loss를 결합하여 사용하고, Prior Association에서는 학습 가능한 가우시안 분포, 그리고 최적화에서는 Minimax 방식을 사용하였다. 각 요소를 하나씩 제거하거나 변화를 주어 모델의 성능이 어떻게 변화하는지에 대한 실험 결과는 Table 2와 같다.

단순히 Association 간의 차이를 최대화로 하는 방식보다 Minmax 방식을 사용하는 경우 크리티컬한 성능 개선을 보이는 것을 확인할 수 있다.
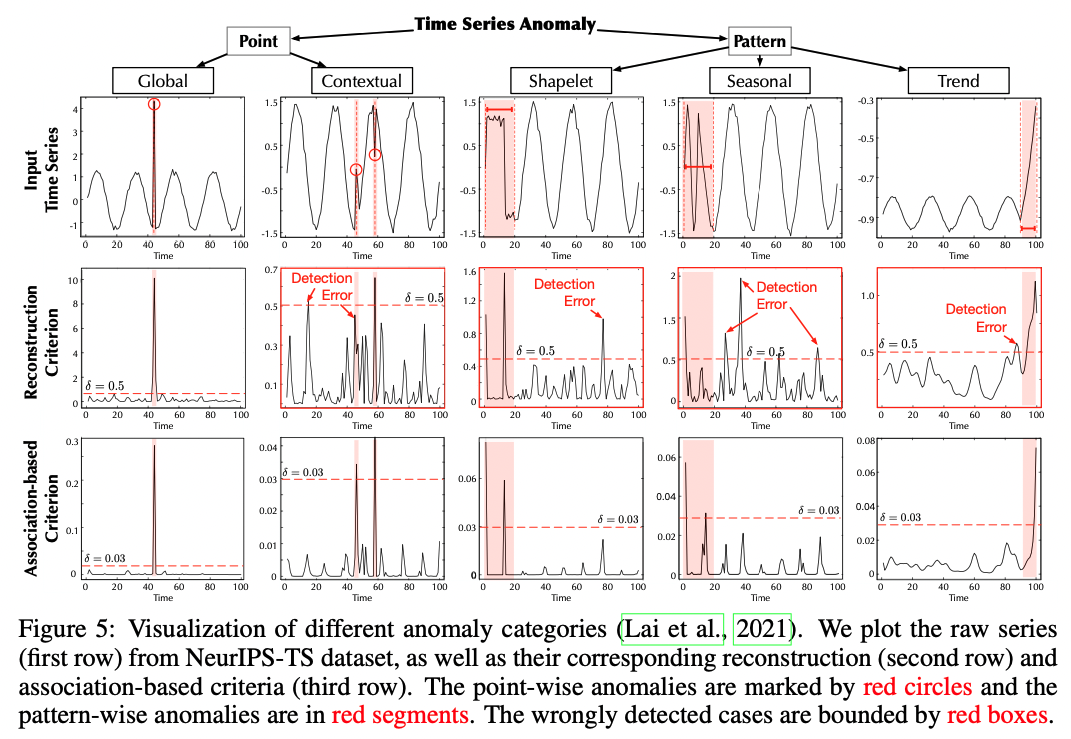

Figure 5에서는 Point, Pattern Anomaly가 존재할 때 Reconstruction Criterion와 Association-based Criterion을 비교 분석한 결과다. Reconstruction Criterion 만을 사용했을 때 Global Point Anomaly에 대해서는 제대로 파악할 수 있으나, Contextual Point Anomaly에 대해서는 제대로 찾아내는 것이 어려운 것을 확인할 수 있고, Pattern Anomaly에 대해서는 대부분의 경우에 Detection Error가 발생하는 것을 확인할 수 있다.

마지막은 최적화 전략에 대한 분석이다. Contrast Value는 정상과 비정상 간의 차이를 의미하며, 값이 높을수록 더 잘 구분하는 것을 의미한다. Minimax 방식을 사용한 경우 Reconstruction, Max 방식에 비해 높은 것을 확인할 수 있다.