Contents
CNN은 여러개의 layer들이 차곡차곡 쌓여있는 구조다. 여러 layer들 중에서 Convolution layer에 대해서 먼저 알아보자.
Convolution layer
32(width)x32(height)x3(depth) image를 가진다. 아래 그림에서 보이는 filter는 parameter를 의미한다고 생각하면 된다. 즉 weight를 나타낸다. depth는 내가 받는 input과 동일해야한다. 동일해야만 filter가 image를 convolve할 수 있다. convolve하는 과정에서 하나의 scalar 값으로 mapping을 한다. 어떠한 image를 convolve하게 되면 똑같이 tensor형태가 나오게 되고, 선형 연산을 통해 나온 scalar 에 activation function을 씌우게 된다.
Convolve : filter가 움직이면서 image를 연산하는 과정을 말한다. filter가 image를 convolve한다.

CNN에서 Convolution layer를 쌓으면 Convolution layer를 쌓을 때 쓰인 filter가 의미하는 결과가 점점 명확해진다. Low-level filter는 패턴을 찾아내고, Mid-level filter는 object들을 찾아내고 High-level filter에서는 Mid-level보다는 조금 더 구체적인 형상을 띄게 된다. 이런 식으로 High-level extraction이 가능하기 때문에 CNN의 성능이 좋다고 한다.
Convolution Layer : Detail
Hyperparameter : spatial extent(receptive field), depth, stride(filter가 image내에서 움직이는 보폭), zero-padding(본 width와 height을 보존하기 위해 zero-padding을 사용한다. )
spatial extent & stride
gray scale의 image라고 생각해보자. (RGB channel이 하나인) 그럼 아래 이미지는 N x N image일 것이다. F x F receptive field를 가지는 filter를 통해 image를 convolve할 때 출력되는 avtivation map(output size)의 size를 알고 싶을 경우 다음 공식을 사용한다. 예를들어 1칸씩 움직인다고 하면 5 by 5의 새로운 tensor가 생긴다.
Zero - padding
zero-padding은 경계를 0으로 채운다는 의미다. CNN에서 image를 계속해서 convolve하게 되면 width와 height이 계속해서 줄어들게 된다. 그렇게 되면 공간적인 정보가 계속해서 줄어들게 되고, 그 과정에서 공간적인 정보를 보존하기 위해 convolution을 거치기 전에 zero-padding을 사용해 image size 를 키워 convolve를 하면 원래 image가 유지되게 된다. 즉 zero-padding은 input과 output의 image size를 똑같이 맞춰주기 위해 주로 사용한다.
Pooling layer
어떤 convolution layer를 거쳐서 나온 tensor의 크기를 줄이려면 pooling layer를 거쳐서 줄이게 된다. pooling layer를 거치게 되면 width와 height가 줄어들게 되는데, 이것은 공간적인 정보를 줄이게 되는 것이다. 과연 pooling layer를 거치는 것이 좋은가? CNN에서는 pooling layer를 거치면서 공간적인 정보를 조금씩 없애는 대신에 내가 탐지하고 싶은 object를 조금 더 찾아내는 representation을 만들어 낸다고 볼 수 있다. pooling layer는 activation function에 독립적으로 적용이 된다.
hyperparameter : spatial extent(receptive field가 아닌 pooling layer가 적용되는 크기), stride
224x224x64 의 tensor에 pooling을 적용하게 되면 112x112x64로 depth는 유지하고 width와 height은 반으로 줄게 된다. 이 과정을 down sampling이라고도 하고 max pooling이라고도 한다. max pooling 기법은 spatial extent안에 있는 값들 중 최댓값만 뽑아서 넘겨주는 기법이다.
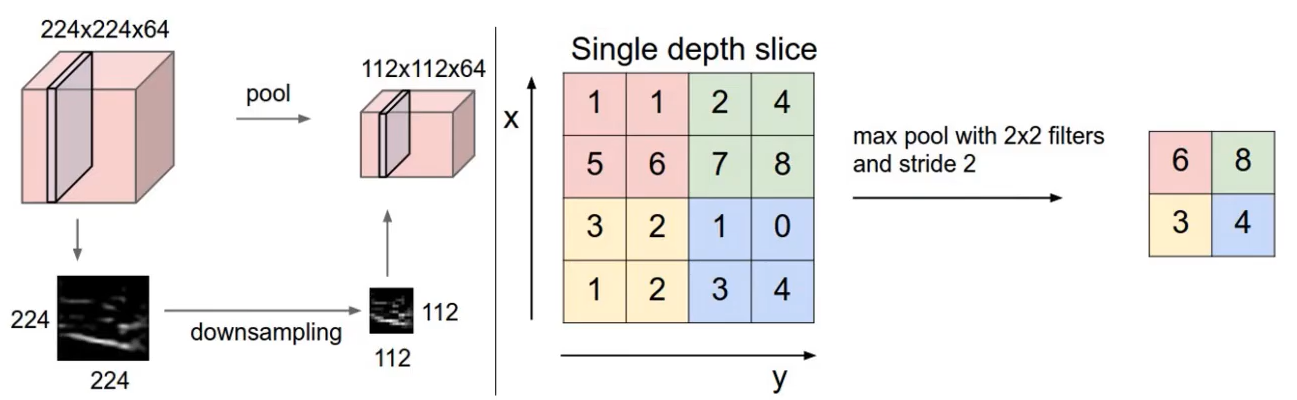
Normalization layer & Fully-connected layer
Normalization layer
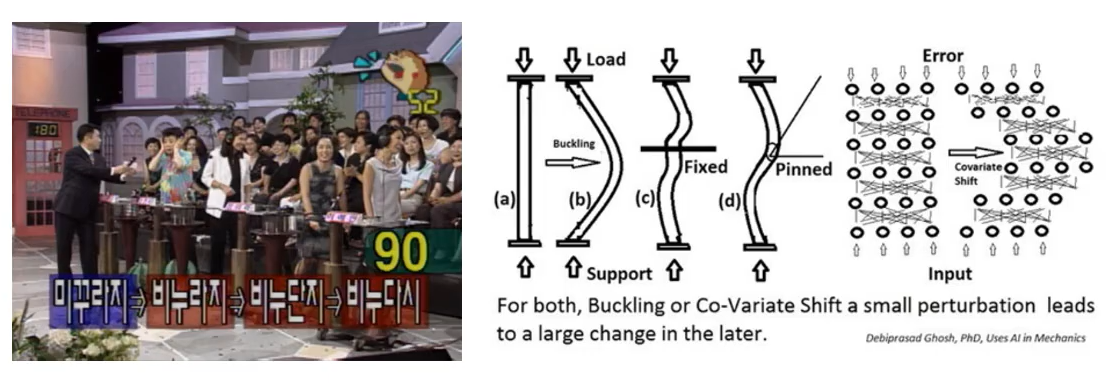
Normalization layer는 학습의 속도를 빨리 하기 위해서 말그대로 normalize를 layer다. 최근 CNN model들은 Batch Normalization(BN)을 활용한다. 기존의 Neural Network에는 internal covariate shift problem이 있었다. 왼쪽의 그림을 보면 input값을 미꾸라지로 전달을 했는데 점점 layer를 거쳐가면서 비누라지, 비누단지로 변형되며 output으로는 비누다시가 출력되었다. 우리가 처음 NN를 학습하게 되면 Batch단위로 학습을 하게 된다. 처음 Batch단위로 weight들이 initialization 하게 되고 forward를 진행하고 backprop을 하게 된다. batch단위의 weight들이 아무리 비슷한 값을 가진다 하더라도 실제로 학습이 진행되어 가면서 달라지게 된다. 이렇게 hidden layer의 값들이 바뀌는 문제점들을 internal covariate shift problem이라고 한다. 이 문제를 Batch Normalization이 여지껏 잘 해결해주고 있었기 때문에 CNN에서 BN를 활용한다.
Fully-connected layer
Artifical Neural Network에서 나오는 fully-connected와 동일하다. fully-connected layer는 실제로 convolution layer로도 바꿔서 구조를 만들어도 되는데, fully-connected layer와 convolution layer 둘다
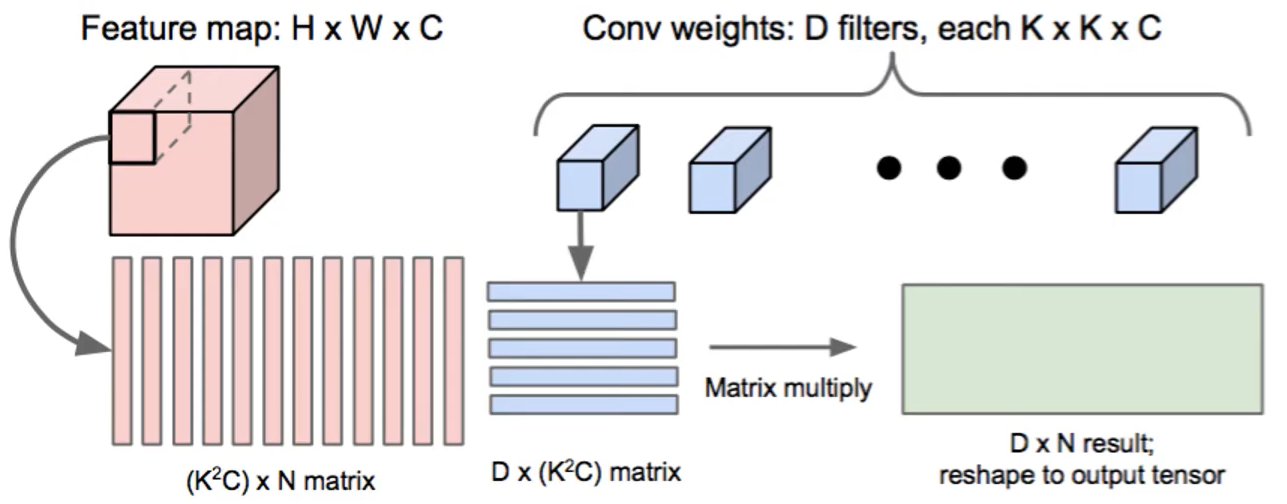
왼쪽 그림은 Image2col이라는 방식이라고도 불린다. 실제로는 우리가 tensor를 연산한다고 하지만 선형대수 library가 계산이 빠르기 때문에 이 친구를 vector의 형태로 바꾸어 놓고 연산을 하는 것이 더 빠르다는 뜻이다. Feature map이 HxWxC의 구조를 가지고 있다고 하자. 우리가 오른쪽 그림의 tensor에 filter를 적용시키려면 특정 KxK의 field를 가진 filter D개를 적용시킬 것이다. python 에서는 각각 적용되는 filter를 아래와 같이(빨간색) vector화 시킨다. 출력된 vector를 matrix형태로 쌓을 수 있게 되고, image의 구역 하나를 matrix의 column vector로 볼 수 있다. 그다음 image에 적용될 filter를 파란색 상자와 같은 vector형태로 바꾼다. 각각의 vector를 행렬곱을 하게되면 전체의 filter에 대해서 연산이 되면서 결과를 채우게 된다.
Converting Fully-Connected Layer to Convolution Layers
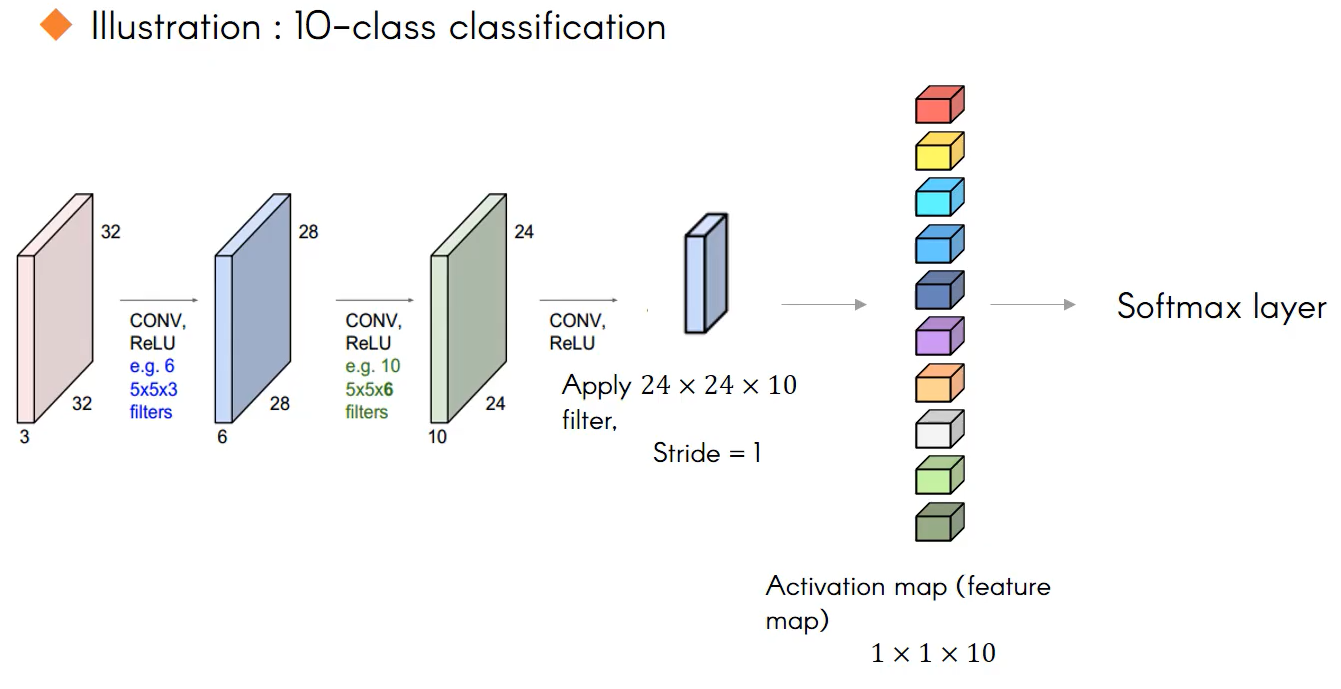
fully-Conneted Layer를 사용하게되면 아래의 그림에서 24x24x10 activation map을 vector형태로 펼쳐서 각각 계산을 해주게 될 것이다. 이 과정을 거치지 않고 filter가 activation map을 convolve하는 과정으로 바꾸어보자. 어쨌든 우리는 output이 길이가 10인 vector로 나오는 것이 목표다. 그럼 24x24x10인 filter를 한 번 생각해보자(아래와 같은). 해당 filter를 24x24x10 activation map에 convolve 시키면 scalar가 하나만 출력이 된다. 그럼 이런 filter가 10개가 있다고 생각해보자. 이 연산을 진행하게 되면 오른쪽에 생기는 vector는 1x1x10의 tensor로 출력된다. 이 tensor를 element wise로 Softmax layer를 거치면 우리가 원하는 각각의 값의 확률이 할당된다. 이런 방식으로 fully-connected layer를 convolution layer로 대체할 수 있다.
'Deep Learning > CS231N' 카테고리의 다른 글
| [CS231N] spatial localization and object detection (0) | 2021.07.19 |
|---|---|
| [CS231N] CNN 기반 모델의 종류(LeNet, AlexNet, ZFNet, VVGNet, GoogleNet, ResNet, DenseNet) (0) | 2021.07.14 |
| [CS231N] Convolution Neural Networks(CNN) (2) | 2021.07.14 |
| [CS231N] Optimization의 종류 - SGD부터 Adam까지 (0) | 2021.07.12 |
| [CS231N] 활성화 함수(Activation Fucntion)의 종류 (0) | 2021.07.08 |