Contents
ImageNet에서 유명한 CNN model 을 설명하는 파트다.
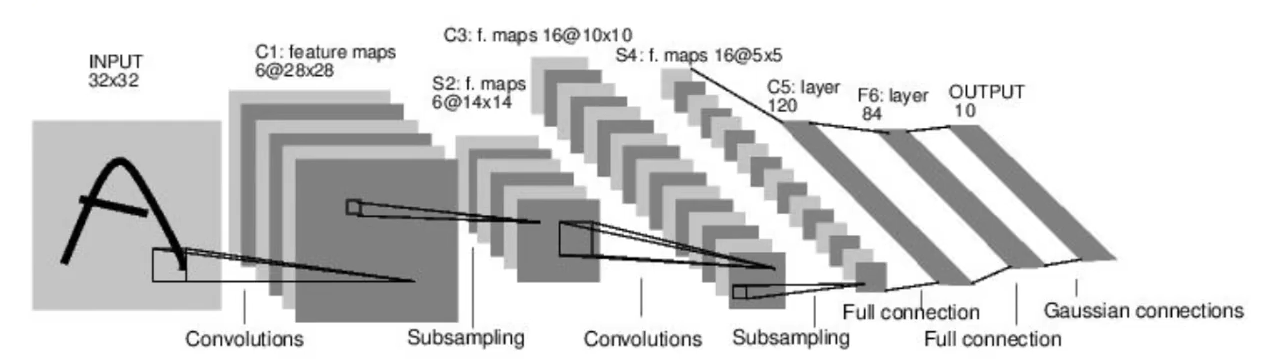
LeNet - 5
LeNet - 5 는 LeNet 모델 중 가장 최근 모델이며 Yann LeCun 연구실에서 1990년대에 만들어졌다. 우편번호나 숫자를 인식하는데 활용되었다. LeNet구조가 지금의 CNN과 큰 다른점이 없다는 것이 핵심이다. Convolution과 subsampling이 쓰이고 feature map을 일자로 펼치는 fully-connection으로 연결을 했다.
AlexNet
AlexNet은 ILSVRC 2012 에서 우승한 모델이고, 이 때 당시 AlexNet 모델에 인해 딥러닝에 혁명이 일었다고 볼 수 있다. 왜냐하면 AlexNet이 CNN 구조로 과거의 top 5 error를 크게 줄였기 때문이다. 그 이후로 image neural network에서 CNN기법을 사용하기 시작했다. AlexNet은 227x227x3 의 input이 96개의 11x11 filter로 stride는 4로주고 zero-padding은 적용하지 않았다. 이러한 구조로 진행이 되는데 여기서 특이한 점은 96개 filter를 한 번에 적용한 것이 아니라 양쪽으로 나누어 GPU를 2개 사용하여 분석을 진행했다고 한다.
parameter 수를 생각할 때 11x11 filter를 사용하는 것은 그다지 좋은 것이 아니다. 11x11 filter를 사용하면 receptive field, 즉 하나의 kernel이 볼 수 있는 이미지의 영역은 커지지만, parameter의 수는 filter의 사이즈 x 채널수로 계산되기 때문에 11x11 filter를 사용하게 되면 파라미터수가 엄청나게 커지는 결과를 초래하기 때문이다.
그 다음으론 convolution layer를 지나고 바로 max pooling을 하게되는데 3x3 filter로 stride를 2를 주고 convolve를 해서 한 부분이 겹치게 되는 것을 볼 수 있다. 그 후 Normalization 을 사용했는데 이때에는 Batch Normalization 을 사용하기 전이라 기존의 Normalization 을 사용했다.
AlexNet이 우승할 수 있었던 이유 중 하나는 ReLU activation function을 사용한 것이다. ReLU는 다른 activate function에 비해 layer를 깊게 쌓음에 있어 발생할 수 있는 vanishing gradient 등의 문제에 대해서 상대적으로 덜 민감하다. 두 번째 이유는 두개의 GPU를 사용했다는 것이고, Overapping pooling과 Data augmentation, Dropout을 사용했기 때문이다.

ZFNet
ZFNet은 사실 AlexNet의 구조와 큰 차이가 없다. 실제로 AlexNet에 쓰였던 parameter를 살짝 손본 정도인데 성능이 향상되었다. parameter를 손본 기법에 대해서 알아보자. CNN를 잘 training하려면 intermediate layer에 그 filter들이 어떻게 학습되는지를 잘 봐야된다는 것이다. 실제로 filter를 학습하는 방법이 ZFNet이 나오기 전에는 없었다. 여기서 나온 방법이 Deconvnet이다. Rectified Feature Maps을 보면 max pooling을 할 때 값들이 Pooled Maps로 이동하게 된다. 이 값들이 ReLU를 적용한 다음 계속 위로 보내게 된다. 활성화된 픽셀(max pooling 된 값)의 위치를 기억해두고 똑같이 ReLU함수를 적용하여 unpooled하게 된다. 이런 과정을 통해서 Reconstruction을 하면 filter를 볼 수 있다는 것이다.
intermediate layer의 filter들을 시각화하면 AlexNet보다 조금 더 구체적으로 특징들을 잡아내는 것을 볼 수 있다.


VGGNET
VGGNET은 ILSVRC 2014에서 2등을 한 모델이다. 이 대회에서 1등을 한 모델은 GoogLeNet인데 굉장히 사용하기가 복잡하고 실제로 google 직원들은 잘 하지만 다른 연구자들이 GoogLeNet을 사용하게 되면 그만큼 성능이 나오지 않는다고 한다. hyperparameter를 tuning 하는 것을 google이 잘한다...
VGGNET은 CNN가 depth가 깊어지면 성능이 더 좋아진다는 것을 보여준 모델이다. AlexNet이나 ZFNet은 Convolution layer가 굉장히 적다. 그렇게 depth가 깊은 모델이 아니라는 것이다. VGGNet의 경우 아래 그림만 봐도 AlexNet에 비해서 Conv layer가 굉장히 많다. 또 AlexNet의 경우 3 by 3, 5 by 5 등 여러가지 방법으로 convolution 하게 되는데 VGGNET의 경우는 오로지 3 by 3 filter로 convolution을 하게 된다. ( stride = 1, padding = 1 ) 단순한 구조의 모형을 깊게 쌓았음에도 불구하고 top 5 error가 크게 줄어든 것을 볼 수 있다.
receptive field 차원에서는 3x3 conv를 두 번 사용하는 것과 5x5 conv 를 한 번 사용하는 것은 동일하다. 왜냐하면 3x3 conv 의 한 pixel 내에서 이전 3x3 conv layer의 정보를 담고 있기 때문이다. 그런데도 3x3 conv 를 사용하는 것이 왜 더 좋은가? parameter 수를 계산해보자. 3x3 conv 를 두 번 사용한 경우 3x3x128x123 + 3x3x128x128 = 294,912개가 되고, 5x5 conv 를 사용한 경우 5x5x128x128 = 409,600 개로 parameter 수는 대략 1.5배 가량의 수가 늘어난다. 같은 receptive field를 갖는 경우 3x3 filter를 두 번 사용하는 것이 더 좋은 Generalization Performance를 가진다.

GoogLeNet
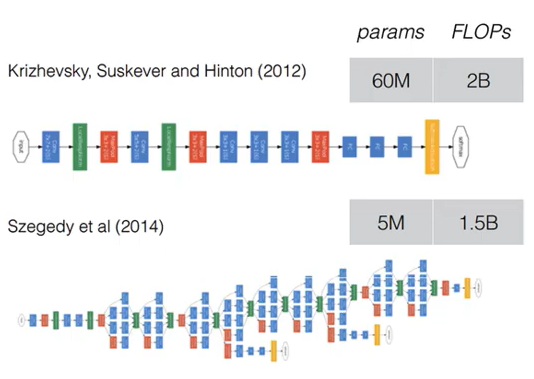
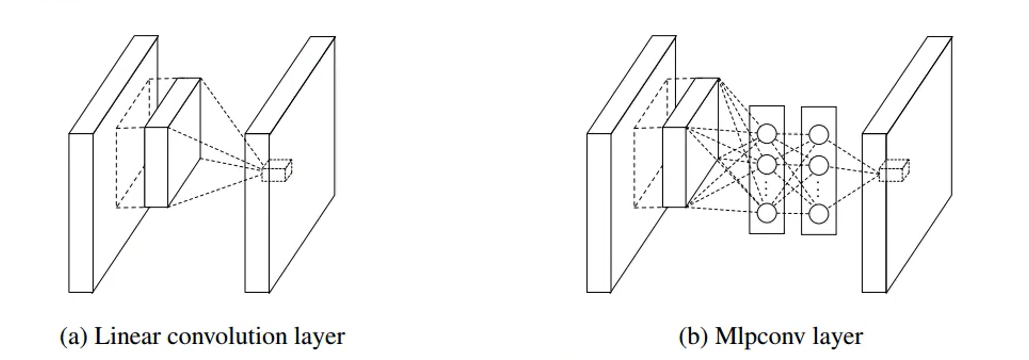
GoogLeNet은 위에서도 말했다시피 ILSVRC 2014 에서 우승한 모델이다. GoogLeNet과 AlexNet을 비교해보면 GoogLeNet이 depth가 더 깊기도 하고 width도 더 두꺼운데, parameter의 개수를 보면 어마어마하게 줄었다는 것을 볼 수 있다. GoogLeNet에서는 inception Module이 개념이 도입된다. filter 연산은 선형 연산인데 filter 연산을 비선형으로 연산을 하게되면 더 많은 정보를 찾을 수 있지 않을까 라는 컨셉에서 나온 모듈이 inception module이다. GoogLeNet을 보면 Network 구조 안에 Network 처럼 생긴 Layer가 존재한다. 이런 구조를 Network In Network(NIN) 구조라고 지칭한다.
Network in network라는 논문에서 제안하는게 filter 연산을 Artifitial Neural Network로 하겠다는 것이다. ANN의 특징이 비선형 모델이기 때문에 과거의 filter 연산은 선형이었던 것을 filter의 연산마저 비선형인 ANN로 한다는 내용이다. GoogLeNet에서는 이 방법론을 묘사하여 1x1 Convolution 연산을 활용했다( Dimenionality reduction ! ) depth가 줄어들면서 parameter의 수가 급격하게 줄어들게 된다. 1x1 Convolution 연산이 선형에 1 layer과도 매칭시켜서 생각을 해볼 수 있다. GoogLeNet을 보면 Network 구조 안에 Network 처럼 생긴 Layer가 존재한다. 이런 구조를 Network In Network(NIN) 구조라고 지칭한다.
inception Block 을 보면 3x3 혹은 3x3 layer를 사용하기 전에 1x1 conv 를 추가한다. 입력이 128 채널, 출력이 128채널인 이미지를 예로 들어보자. 3x3 convolution 연산을 하게 되면 3x3x128x128 =147, 456 개의 parameter 수를 가진다. 하지만 그 사이에 1x1 convolution 연산을 통해 32채널로 축소시키는 연산을 하면 1x1x128x32 + 3x3x32x128 = 40,960개로 parameter수가 급격하게 감소하는 것을 확인할 수 있다.


ResNet
ResNet 모델은 ILSVRC 2015에서 우승한 모델이다. ResNet모델의 특징적인 방법은 skip connection이다. ResNet은 특정한 모델을 지칭하는 것이 아니라 skip connection을하는 concept 자체라고 생각하는 것이 더 좋다. VGGNET에서 convolution layer를 깊게 쌓으면 더 좋은 것을 확인 할 수 있었다. skip connection 이 없는 경우 layer의 수가 적은 것이 오히려 error가 더 낮게 나온다. 이러한 문제를 degeneration problem이라고 한다. degeneration problem은 일정 layer를 넘어가면 error가 내려가지 않고 다시 올라가는 현상을 말한다. 이 degeneration problem을 ResNet에서는 skip connection 을 통해 해결한 것이 아니고 더 뒤로 늦춘 것이다.


ResNet에서는 Bottlenect architecture가 들어간다. 여기도 GoogLeNet에서 1x1 convolution을 사용한 이유와 동일하게 parameter의 수를 줄이는 용도로 3x3 convolution을 하기 전에 1x1 convolution을 통해 parameter 수를 줄인다. 마지막에 256 을 통해 output 사이즈를 맞춰준다.

DenseNet
ResNet의 경우 마지막에 skip connection을 통해 convolution을 통해 나온 어떤 값을 더해주는데, DenseNet은 더하게 되면 두 개의 값이 섞여버리니 두 값들을 concatenation을 진행한다. 하지만 계속 이어붙이면 parameter수가 2, 4, 8, .. 기하급수적으로 parameter 수가 증가한다. 우리는 parameter를 줄이는데에도 목적이 있기 때문에 해당 논문에서는 Dense Block을 통해서 parameter수를 늘리고 그 후 1x1 Convolution, 2x2 AvgPooling을 집어넣어 다시 parameter수를 줄이는 과정을 반복하게 된다.



결론
VGGnet에서 3x3 block을 반복해서 쓰는 것이 더 좋은 것을 확인
GoogLeNet에서는 1x1 convolution 연산을 통해 parameter 수를 줄이는 것을 확인
ResNet에서는 skip-connection을 통해 이전 layer의 값을 받아오는 것이 성능이 더 좋다는 것을 확인
DenseNet에서는 concatenation하는 것을 확인
'Deep Learning > CS231N' 카테고리의 다른 글
| [CS231N] Object Detection의 종류 (R-CNN, SPPnet, Fast R-CNN, Faster R-CNN, YOLO까지) (0) | 2021.07.19 |
|---|---|
| [CS231N] spatial localization and object detection (0) | 2021.07.19 |
| [CS231N] Stride, Padding, Pooling layer 란? (0) | 2021.07.14 |
| [CS231N] Convolution Neural Networks(CNN) (2) | 2021.07.14 |
| [CS231N] Optimization의 종류 - SGD부터 Adam까지 (0) | 2021.07.12 |