ANOVA
ANOVA(Analysis of variance)는 두 개가 아닌 여러 모집단 간의 평균의 동일성을 검정한다. 집단을 구분하는 범주형 변수가 한 개인 경우를 일원분산분석(one-way ANOVA)라고 하며, 두 개인 경우 이원분산분석(two-way ANOVA)라고 한다. 이론상으로는 삼원분산분석, 사원분산분석등 더 많은 집단을 구분하는 것이 가능하지만 해석하는데 있어서 어려움이 있기 때문에 한 개 혹은 두개의 범주형 변수를 다룬다.
예를 들어 수학학원A, B가 있다고 하자. 학생들은 두 학원 모두 다니는 것은 불가하며 한 번에 한 학원만 다닐 수 있다고 가정하자. 여기서 집단을 구분하는 학원은 독립변수며, 수학점수는 종속변수다. 집단 간 one-way ANOVA를 시행할 수 있으며, 분산을 비교하기 때문에 F-test를 사용한다. F-test를 통해 귀무가설을 기각하게 되면, 두 학원에 다니는 학생들의 수학 성적이 차이가 있다라는 유의미한 결과를 도출해낼 수 있다.
수학학원 A에 대해서 두달 학원을 다닌 후 수학시험을 쳐서 성적을 매기고 넉달 뒤 수학 시험을 쳐서 평균을 비교하게 되면 집단 내 one-way ANOVA라고 할 수 있다. 이 경우에는 학원을 다닌 기간이 독립변수며, 수학성적이 종속변수가 된다. 위 실험은 동일한 학생에게 두 번 시험을 치루는 일이 발생하기 때문에 반복측정 분산분석이라고도 한다.
위 두 예시를 합쳐서 평가를 하는 경우 4가지 그룹으로 묶이게 된다. 첫 번째 A학원에 4주 다녔을 때의 수학성적 , 두 번째 A학원에 16주 다녔을 때의 수학성적, 세 번째 B학원에 4주 다녔을 때의 수학성적 마지막으로 B학원에 16주 다녔을 때의 수학성적으로 묶을 수 있다. 이때 학원의 영향과 다닌 시간의 영향을 주효과 라고 하고 나머지 학원과 기간 간 상호작용의 영향을 상호작용효과라고 한다. 학원과 기간은 독립변수며, 수학성적은 종속변수로 둔다. 이 경우에는 집단을 구분하는 방법이 두 개이므로 이원분산분석이다. 또한 같은 실험 대상자에게 반복적인 측정이 이루어지기 때문에 반복측정 분산분석이기도 하다.
하지만 수학성적은 학교와 학원과의 거리와 밀접한 관련이 있을 수 있다. 앞서 설계에서 두 가지 학원에 무작위로 할당하기는 했지만 두 학원 집단에 포함된 실험 참여자들의 학교와 학원의 거리는 다를 수 있다. 만약 실험 참여자의 해당 거리를 사전에 측정하여 데이터를 갖고 있다면 실험 참여자의 해당 거리를 통제해 순수한 차이를 검정할 수 있을 것이다. 이때 학교와 학원의 거리 변수를 공변량(covariate)라고 하며, 이러한 실험 설계를 공분산분석(analysis of covariance, ANCOVA)이라고 한다. 공변량은 연속형 변수를 가정한다.
지금까지 실험설계에서는 수학성적을 측정하기 위한 종속변수로 수학성적 하나만을 사용했다. 그러나 연구의 타당성을 높이기 위해 측정 지표를 추가할 수 있다. ( 국어, 영어 점수 등 ) 두 개 이상의 종속변수를 포함하는 실험설계를 다변량 분산분석(multivariate analysis of variance, MANOVA)이라고 한다. 여기에 공변량이 추가가 되면 다변량 공분산분석(multivariate analysis of covariance, MANCOVA)이 된다.
F-test
우리가 분산분석을 하고 난 후 나온 값을 가지고 평가를 해야되는데, 이때 F-test를 사용하여 가설을 검정한다. F-test는 집단 간 분산과 집단 내 분산의 비로 계산되는 F-value를 가설검정을 위한 test-statistic으로 사용한다. 집단 간 평균이 다르다는 것은 기본적으로 각 집단의 평균이 서로 멀리 떨어져 있다는 뜻이고, 이는 집단 평균이 퍼져 있는 정도를 나타내는 집단평균의 분산이 크다는 의미다. 그렇기 때문에 집단 간 분산 차이를 통해서 두 집단을 평가하게 된다. 결론적으로 집단 간 분간이 클수록, 집단 내 분산이 작을수록 집단 평균이 다를 가능성이 증가한다.
$F = \frac{U_1 / v_1 }{U_2 / v_2} \sim F_{v_1, v_2} $
$v_1$ = $U_1$의 자유도, $v_2$ = $U_2$의 자유도
$U_1 = \frac{(n_1-1)s_1^2}{\sigma_1^2} \sim \boldsymbol{\chi}^2_{n_1-1},\ U_2 = \frac{(n_2-1)s_2^2}{\sigma_2^2} \sim \boldsymbol{\chi}^2_{n_2-1} $
$ F = \frac{U_1 / v_1}{U_2 / v_2} = \frac{ \frac{(n_1-1)s_1^2}{\sigma_1^2 \cdot v_1} }{\frac{(n_2-1)s_2^2}{\sigma_2^2 \cdot v_2}} $
$= \frac{s_1^2 / \sigma_1^2}{s_2^2 / \sigma_2^2} = \frac{s_1^2 / s_2^2}{\sigma_1^2 / \sigma^2_2} \sim F_{n_1 -1, n_2 - 1} $
위 처럼 Chisq-test에서 F-test를 유도할 수 있다. 그리고 분모와 분자의 자유도를 서로 바뀌어 있는 F-test는 다음과 같은 중요한 성질이 성립한다.
$F_{v_1,v_2,\alpha} = \frac{1}{F_{v_2,v_1,(1-\alpha)}}$
Z분포는 t분포로 근사할 수 있다. 그리고 t분포는 Chiq분포와 연관성이 있다. 이런 관계를 반복해내면 다음과 같은 재미있는 관계를 유도해낼 수 있다.
$ t = \frac{Z}{\sqrt{U/v}} \sim t_v$
$ \rightarrow t^2 = \frac{Z^2/1}{U/v} \sim F_{1,v}\ \ ( \because \boldsymbol{Z^2} = \boldsymbol{\chi^2} ) $
F - test를 통해 각 값을 구했다면 MStreatment와 MSerror를 통해 해당 집단 간 평균의 차이가 있는지에 대해 검정할 수 있을 것이다. 직접 일일히 손으로 계산하는 건 힘들기 때문에 코드로 작성해보자.
str(InsectSprays)
# 평균은 F가 가장 크다.
tapply(InsectSprays$count, InsectSprays$spray, mean)
# 표분편차는 F가 가장 크다.
tapply(InsectSprays$count, InsectSprays$spray, sd)
# 길이는 동일하다.
tapply(InsectSprays$count, InsectSprays$spray, length)
if (!require('gplots') install.packages('gplots')
library('gplots')
plotmeans(count ~ spray, data = InsectSprays,
barcol = 'tomato', col = 'cornflowerblue', lwd = 2, barwidth = 3,
xlab = 'Type of Sprays', ylab = 'Insect Count',
main = 'Performance of Insect Sprays \n with 95% Confidence Interval of Mean')
# 1
spray.aov <- aov(count ~ spray, data = InsectSprays)
spray.aov
summary(spray.aov)
# 2
anova(lm(count ~ spray, data = InsectSprays))
spray.aov를 통해 anova를 시행하고, summary로 anova 안의 SSE, MSE, 등 분산값과 F-value 등을 뽑아낼 수 있다. linear model 함수를 통해 anova로 바로 출력해내는 방법도 존재한다. 위 결과를 토대로 귀무가설을 기각할 수 있으며, 집단 간 평균의 차이가 존재한다는 결과를 도출해낼 수 있다.
위에서 집단 간 평균 차이가 있다는 것을 확인 했다. 하지만 집단 간 평균의 차이가 있다고만 알고 어떤 집단 간에 차이가 있는지에 대해서는 결과를 도출해내지 못했다. 이럴때 사용할 수 있는 것이 사후 분석이다. 사후 분석의 종류로는 Tukey, duncan, sheffe, bonferroni 등이 있다. 우리는 Tukey에 대해서만 다뤄보도록 하자.
spray.compare <- TukeyHSD(spray.aov)
# p adj : 평균 차이에 대한 p-value
spray.compare
if (!require('multcompView')) install.packages('multcompView')
library(multcompView)
plot(spray.compare , las=1 , col="blue")
spray.compare$spray['D-C', ]
# mulcomp ----
# 조금더 다양한 다중비교를 위한 방법을 제공한다.
if (!require('multcomp')) install.packages('multcomp')
library(multcomp)
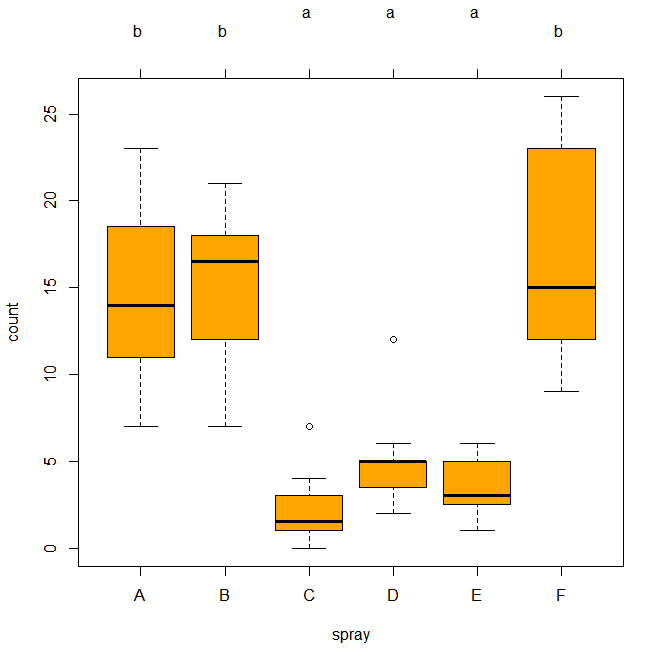
tuk.hsd <- glht(model=spray.aov, linfct=mcp(spray='Tukey'))
plot(cld(tuk.hsd, level=0.05), col = 'orange')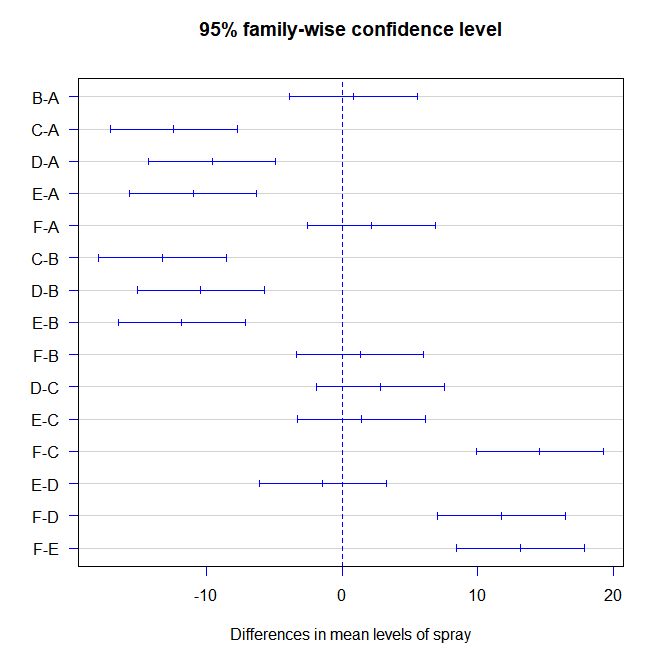
'Mathematics > Statistics' 카테고리의 다른 글
| [Statistics] independent of probability variable (0) | 2021.10.19 |
|---|---|
| [Statistics] Chi-squared test (0) | 2021.10.17 |
| [Statistics] T test with R (0) | 2021.09.23 |
| [Bayesian] Gaussian process (0) | 2021.08.08 |
| [Bayesian] Bayes' Rule (0) | 2021.07.25 |