추천시스템에서는 어떤 평가함수가 있을까? 우리는 평가함수에 대해서 다양하게 알고 있어야 한다. 왜냐하면 평가함수는 도메인이나 목적에 따라서 다른 평가함수를 적용해서 사용해야 해당 추천시스템이 제대로 적용되고 있는지 알 수 있기 때문이다.
1. 내가 추천해준 영화를 고객이 보았는가?
2. 내가 추천해준 영화를 고객이 높은 점수로 평점을 주었는가?
1번의 경우에는 실제 영화를 해당 고객이 시청했다면 성공으로 볼 수 있지만 2번의 경우에는 실제 고객의 만족도까지 높아야 되기 때문에 고객의 만족도까지 고려해서 평가한 것이다. 기사의 경우 기사를 확인하고 체류시간에 따라 평가할 수 있다.
Accuracy
- 정확도는 여러 예측 모델에서 가장 많이 쓰이는 평가지표 중 하나이며, 추천시스템에서는 내가 추천해준 영화를 보았는가? vs 보지 않았는가? 을 통해서 평가를 할 수 있다. 내가 추천해주는 영화를 많이 볼수록 추천하지 않은 영화를 보지 않을수록 정확도는 상승한다. 하지만 추천하지 않은 영화의 수는 추천한 영화의 수에 비해 굉장히 많고 그렇기 때문에 편향된 결과를 얻을 수 있다. 그렇기 때문에 추천을 해준 영화 중 본 영화로만 평가를 매겨주어야 한다.
$accuracy(y, \hat{y}) = {1 \over n}\underset{i=0}{\overset{n-1}{\Sigma}} 1(\hat{y_{i}} = y_{i}),\ \ ( n = size\ of\ samples)$
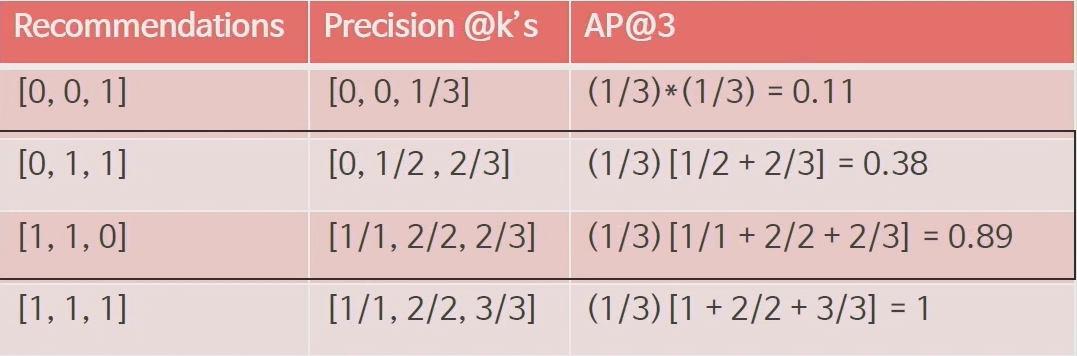
MAP(Mean Average Precision)
precision의 결과를 가지고 precision의 average를 구하는 것이다. 추천을 해주었을 때 맞은 경우 1, 틀리면 0 으로 평가가 된다. AP는 Precision @k's를 평균낸 값이며 MAP@4는 4명의 사용자의 AP를 평균낸 값이다. MAP의 경우 추천의 순서에 따라서 값이 차이가 난다. 왜냐하면 추천을 해줄때 상위 n개를 추천해주는데 가장 볼 확률이 높은 아이템을 추천해주었지만 그 상품은 구매 혹은 보지않았기 때문에 당연히 precision이 낮게 나올 수 밖에 없다. 또 상위 k개의 추천에 대해서만 평가를 하기 때문에 k를 바꿔가면서 상위 몇 개를 추천하는게 좋을지도 결정할 수 있다.
$Precision = {True Positive \over Actual Results } or { True Positive \over True Positive + False Positive } $
NDCG(Normaized Discounted Cumulative Gain)
NDCG는 MAP의 문제점을 보완한 평가지표다. NDCG는 원래 추천엔진이 아니라 검색엔진에서 많이 활용된 평가 메트릭이고, 사용자마다 추천해주는 상품의 갯수가 다를 수 있는데 갯수가 다르더라도 추천을 해줄 수 있다. 검색과 관련있는 문서들을 추천해주는 방식으로 생각할 수 있으며 이 경우 NDCG를 사용하여 추천엔진을 평가할 수 있다. NDCG를 이해하기 위해서는 Cumulative Gain과 Discounted Cumulative Gain을 이해할 필요가 있다.
Cumulative Gain(CG)
상위 n개의 추천 결과들의 관련성(relevance)을 합한 누적값이다. relevance는 단순히 관련이 있는지 없는지에 따라 1 혹은 0을 갖는 binary value 이거나 또는 문제에 따라 세분화된 값을 가질 수 있다. 식을 보면 알 수 있듯 상위 n개의 추천 결과들을 동일한 비중으로 계산한다. 눈으로 보기에는 B가 A보다 더 나은 추천 결과인 것을 알지만 CG의 관점에서는 똑같다.
$Cumulative\ Gain(CG) = \underset{i=1}{\overset{n}{\Sigma}} relevance_i $
$Set\ A = [0, 0, 1, 1, 1]$
$Set\ B = [1, 1, 1, 0, 0]$
$CG_A = 0+0+1+1+1 = 3$
$CG_B = 1+1+1+0+0 = 3$
Discounted Cumulative Gain(DCG)
DCG는 기존의 CG의 랭킹 순서에 따라 점점 비중을 줄여 관련도를 계산하는 방법이다. 하위권 결과에는 패널티를 주는 형태로 계산이 된다. (1) 식과 (2) 식 둘다 사용되지만 (1)식은 Standard 형태고, (2) 식은 랭킹의 순서보다 관련성에 더 큰 비중을 주고싶을 때 사용하게 된다. 이때 relevance식이 binary value 이면 두 식이 같아짐을 알 수 있다.
$DCG = \underset{i=1}{\overset{n}{\Sigma}} {relevance_i \over log_2(i+1)} $
$DCG = \underset{i=1}{\overset{n}{\Sigma}} {2^{relevance_i} -1 \over log_2(i+1)} $
$Set\ A = [2, 3, 3, 1, 2]$
$Set\ B = [3, 3, 2, 2, 1]$
$DCG_A = {2 \over log_2(1+1)} + {3 \over log_2(2+1)} + {3 \over log_2(3+1)} + {1 \over log_2(4+1)} + {2 \over log_2(5+1)} \approx 6.64 $
$DCG_B = {3 \over log_2(1+1)} + {3 \over log_2(2+1)} + {2 \over log_2(3+1)} + {2 \over log_2(4+1)} + {1 \over log_2(5+1)} \approx 7.14 $
DCG는 추천결과의 위치를 고려할 때 좋은 척도로 보이지만 완벽한 척도는 아니다. 다양한 요인에 따라 권장 사항 수가 사용자마다 다를 수 있는데, DCG는 권장 사항의 수에 따라 결과가 달라지기 때문이다. 그에 따라 상한과 하한이 필요하며 모든 추천 점수를 평균하여 최종 점수를 보고 정규화할 필요가 있다. 이것을 반영한 것이 NDCG가 된다. (DCG에 Normalize한 방법) 추천했을 때의 수치와 이상적인 수치를 구해 지표를 구하게 된다.
$Recommendations\ Order = [2, 3, 3, 1, 2]$
$ Ideal\ Order = [3, 3, 2, 2, 1] $
$ iDCG_n = \underset{i=1}{\overset{n}{\Sigma}} { relevance^{ideal}_i \over log_2(i+1)}$
$DCG = {2 \over log_2(1+1)} + {3 \over log_2(2+1)} + {3 \over log_2(3+1)} + {1 \over log_2(4+1)} + {2 \over log_2(5+1)} \approx 6.64 $
$iDCG = {3 \over log_2(1+1)} + {3 \over log_2(2+1)} + {2 \over log_2(3+1)} + {2 \over log_2(4+1)} + {1 \over log_2(5+1)} \approx 7.14 $
$NDCG = {DCG \over iDCG} = {6.64 \over 7.14} \approx 0.93 $
'Deep Learning > Recommender system' 카테고리의 다른 글
| [Recommender System] 협업 필터링(Collaborative Filtering) (0) | 2022.01.13 |
|---|---|
| [Recommender System] Collaborative Filtering, Content-based, Knowledge-based (0) | 2022.01.03 |
| [Recommender System] Neighborhood based method(CF) (0) | 2021.08.18 |
| [Recommender System] TF-IDF (4) | 2021.07.27 |
| [Recommender System] Association Rule (0) | 2021.07.23 |