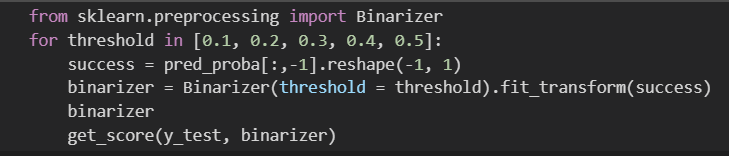
로지스틱 회귀는 이진분류에서 사용되는 모델 중 흔히 쓰이는 모델이라고 보면 된다. 이론적인 부분을 공부하고 싶다면 여기를 눌러서 들어가면 볼 수 있다. 나는 임의로 데이터를 생성하여 분석을 진행했기 때문에 모델의 성능이 좋게 나오지는 않았다. 공식 데이터를 가지고 분석을 수행하면 보다 좋은 결과를 도출할 수 있을 것이다. def sigmoid(z): return 1/(1+np.exp(-z)) def f(x, w, b): return np.dot(x, w) + b def df(x, w, b): return x, 1 def binary_cross_entropy(z, t): return -(t*np.log(z) + (1-t)*np.log(1-z)).mean() 분석을 진행하기 앞서 로지스틱의 수식(sigmoi..