Contents
GCMC는 추천 시스템에 그래프를 접목한 연구 중 하나다. auto-encoder framework를 사용하여 link prediction을 수행한다. SoTA 성능까지 달성한 모델로 추천 시스템과 그래프를 접목한 연구 중 널리 알려진 모델이다.
Introduction
논문의 제목에서도 알 수 있듯 Matrix Completion 관점에서 link prediction task를 수행하는 모델이다. 기본적으로 Interaction data는 사용자와 제품 간의 관계로 이루어진 Bipartitle Graph 형태로 구성되어 있다. 본 논문에서는 Bipartitle Graph를 위한 auto-encoder framework인 GC-MC(Graph Convolution Matrix Completion)를 제안한다. 여기서 Matrix Completion은 사용자가 평가하지 않은 제품 혹은 구매하지 않은 제품은 0으로 표현하는데, 이 값을 채운다는 의미다. 즉, 사용자가 구매하지 않은 제품, 평가하지 않은 제품에 대해서 사용자의 구매 확률 혹은 평점을 예측하는 것이다.
Matrix Completion as link prediction in bipartite graphs
먼저 논문에서 사용한 기호에 대해서 알아보자. 평점 행렬은

본 논문에서는 평점 행렬을 입력으로 사용하고 Graph Auto-Encoder를 사용해 축소 후 다시 복원하여 Link prediction을 수행한다.
Graph auto-encoders
본 논문에서는 auto-encoder를 사용하기 때문에 auto-encoder가 일단 먼지부터 알아보자. auto encoder는 encoder model
Graph Convolutional encoder
본 논문에서는 일반적으로 사용하는 Graph Convolutional Network를 사용한다. GCN은 Message passing과 akwlakr aggregate으로 이루어져 있으며, 아래와 같은 수식으로 표현할 수 있다.
본 논문에서는 평점 1인 신호와 평점 2 나아가 평점 R 인 신호를 별도로 합산하여 계산한다.
최종적으로 Weight Matrix
Bilinear decoder
위 과정을 통해
Model training
Loss function은 negative log likelihood를 통해 최소화하는 방향으로 학습할 수 있다.
본 논문은 Loss function뿐만 아니라 Node dropout, Mini-batching 등을 함께 사용하였으나, 이에 대한 방법은 다른 논문에서도 함께 사용하는 방식이기 때문에 본 글에서는 따로 다루진 않는다.
Vectorized implementation
본 논문에서는 Graph encoder에서 생성한
Input feature representation and side information
본 논문에서는 side information을 추가하면서 cold start를 해결할 수 있다고 한다. 실제 실험에서는 side information을 사용하지 않았으나, side information을 사용하는 경우 아래와 같은 수식으로 사용할 수 있다.
이때
Weight Sharing
위에서 계산한 Latent Vector는 Message Passing 을 통해 각 사용자 혹은 제품으로 전달된다. 그러나 각 평점에 대해 동일한 등급을 가질 필요가 없다. 구체적으로 평점 1을 부여한 값과 평점 5를 부여한 값을 동일하게 가질 필요가 없다. 따라서, 아래와 같은 수식을 통해 평점에 따라 가중치를 달리 부여하고 Weight Matrix를 공유한다.
이와 같이 Weight를 공유하여 더 높은 등급의 가중치가 커지는 형태를 Oridinal Weight Sharing이라고 한다.
Experiments
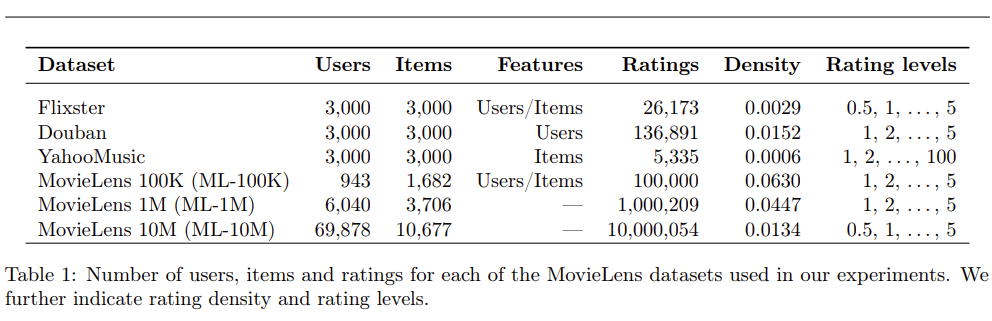
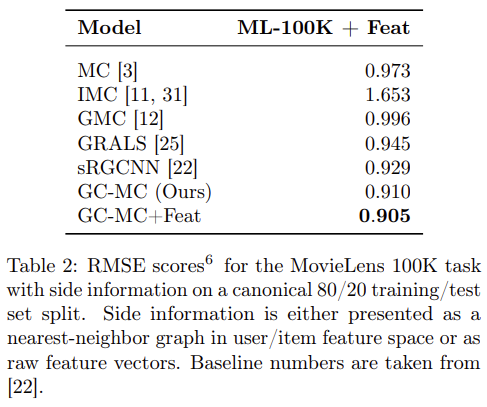
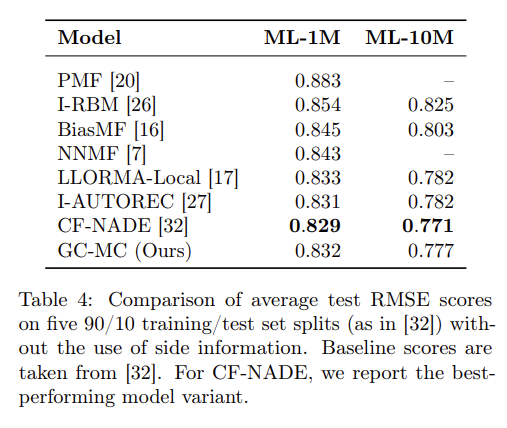
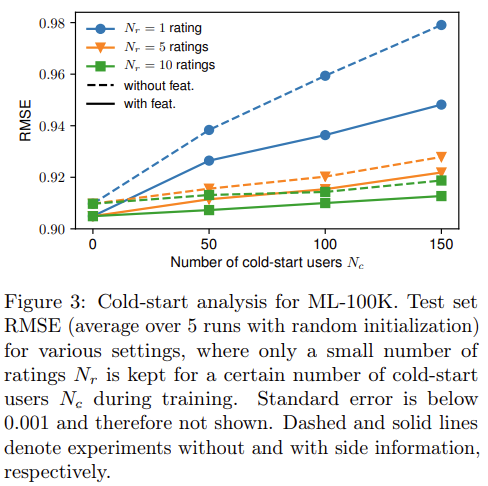
실험의 경우 다양한 방법으로 진행하였다. 실험 결과 본 논문에서 제안하는 GC-MC의 성능이 가장 우수한 것을 확인할 수 있으며, Cold-Start analysis에서도 GC-MC의 장점을 확인할수 있다.