Contents
이미지, 자연어처리 등과 같은 분야에서 BERT, GPT-3, CLIP 등의 대규모 사전 학습 모델의 성능이 우수한 것은 이미 검증되었다. 그러나, User Representation 에서 범용적으로 사용될 수 있는 모델에 대한 연구는 아직 많이 연구되지 않고 있다. 본 연구에서는 Large-Scale User Encoder를 학습함으로써 범용적으로 사용될 수 있는 User Representation 학습이 가능한 Contrastive Learning User Encoder (CLUE)를 제안하였다.
Introduction
비전, 음성 등과 같은 분야에서는 Foundation Model이라고 불리는 Large-Scale Model (BERT, GPT-3, CLIP, etc.)이 자주 제안되고 있으나, User Repesentation, 즉, 추천 시스템 분야에서는 아직 많은 연구가 이루어지지 않고 있다. 본 연구에서는 이를 연구하기 위해 다음과 같은 5가지의 질문을 언급한다. 1) 다양한 소스 데이터에서 학습한 User Representation이 전이 학습을 할 때 모델의 능력이 제대로 발현되는가? 2) 사전 학습과 다운스트림 태스크가 양의 상관관계를 가지는가? 3) 사전 학습된 User Representation이 얼마나 다양한 태스크에서 사용될 수 있는가? 4) 사전 학습 모델의 크기를 키우면 일반화 성능이 향상되는가? 5) 사전 학습 모델의 크기를 키울 때 일반화 성능이 향상된다면, 모델의 크기, Behavior Sequence Length, 배치 크기와 같은 요소들 중 어떤 요소를 확장하여야 하는가? 본 연구에서는 위 질문에 답하기 위해 Contrastive Learning User Encode (CLUE)를 제안하였다. 이름에서도 알 수 있듯, 대조 학습(Contrastive Learning)을 사용하였다.
CLUE
본 연구에서는 User Embedding의 Quality를 향상시키기 위해 Multi-modal Contrastive Learning Framework를 사용한다. 가장 대표적인 Multi-model Contrastive Learning Framework는 CLIP이 있는데, CLIP은 이미지와 텍스트 페어를 인코딩하고, 유사도를 최대화하는 방식으로 학습한다. 그다음으로, 다양한 서비스 사이의 User Semantics을 조정하기 위해 각 제품에 대한 텍스트 정보를 사용한다.

CLUE의 Encoder의 경우 Item Transformer
각 Service에 대한 사용자 로그는
Experiments
본 연구에서 사전학습 시에 사용된 데이터는 검색 엔진과 e-commerce 플랫폼에서 2년 이상 수집된 50B 만큼의 양의 Behavior 데이터를 바탕으로 학습하였다. 그런 다음, 2개월에 한 번 미만으로 로그가 기록된 사용자는 제거하였다. User Behavior 로그에서 수집된 제품 설명(Description)은 Byte-level BPE를 사용하여 토큰화하고, 중복된 Behavior이 있는 경우 하나만 남기고 나머지는 제거하였다.
다운스트림 태스크에서는 Amazon Books, Clothing Shoes and Jewelry 데이터를 사용하고, E-commerce (PCR), web-based cartoon (FWR), news (NVR), marketing messages (MMR), Online travel agency (OTAR) 등의 데이터를 사용하였다. (각 데이터에 대한 상세한 내용은 본 논문의 부록을 참고하면 된다)
실험 결과, 본 연구에서 제안하는 CLUE가 Transformer, LightGCN보다 속도가 빠른 것도 확인할 수 있고, Amazon 데이터와 각 다운스트림 태스크에서 모든 경우에 대해서 성능이 우수한 것을 확인할 수 있다. 이를 통해 CLUE의 Adaptability와 Generality를 확인할 수 있다. Table 4의 경우에는 Online Evaluation (CTR Prediction) 한 결과인데, CLUE의 성능이 가장 우수한 것을 확인할 수 있다. User Group "New"는 지난달 기록이 없는 사용자 그룹을 의미하고, Cold는 하위 10%, Heavy는 상위 10%에 속하는 사용자 그룹을 의미한다.
Figure 2(a)의 경우 Model Size, Batch Size, Sequence Length 등과 같은 파라미터에 대한 성능을 비교하였으며, 모델의 크기가 클수록, Batch Size와 Sequence Length가 커지면 성능이 좋아진다. 모델의 크기가 작은 경우 Batch Size는 작은 값을 가지고 가야 성능이 우수하다는 결과를 확인할 수 있다. Figure 2(b)에서는 모델 크기에 따른 성능을 비교한 것이다. 같은 선에서 각각의 점은 4M ~ 160M 파라미터를 가지는 모델들을 의미한다. Sequence Length가 커질수록, 모델의 크기가 커질수록 성능이 증가한다는 것을 확인할 수 있다. Figure 3은 ICLT Task에서 학습 데이터 사이즈를 1% ~ 100% 다양하게 가져가는 동안의 Step에 따른 성능을 보여주고 있다.
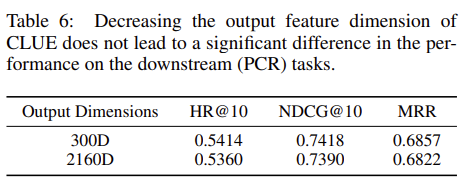
Table 5는 Transformer Layer를 Single로 가지고 가는지, Stacking하는지에 따른 성능을 보여준다. Table 6의 경우 Output 차원의 크기에 따른 추천 성능을 보여준다. 300 차원인 경우 2160 차원인 경우에 비해 성능이 우수한 것을 확인할 수 있다.