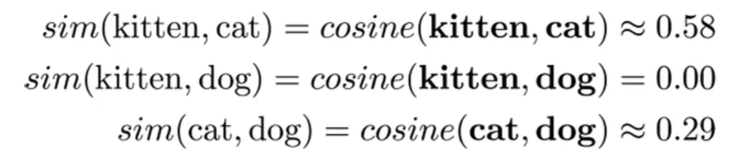[Python] tuple
tuple의 형태와 기초를 다루는 형태로 코드를 작성해보았다. # tuple t1 = () t2 = (1,) t3 = (1, 2, 3) # 괄호를 생략해도 무방 t4 = 1, 2, 3 t5 = ('a', 'b', ('ab', 'cd')) t1, t2, t3, t4, t5 # list 의 값은 변경이 가능하지만 tuple의 값은 변경이 불가능하다. # 지우는 것이 불가능 t1 = 1, 2, 'a', 'b' del t1[0] # error # 변경 불가능 t1[0] = 'c' # error # indexing t1 = 1, 2, 'a', 'b' t1[0] # 1 a = ((1 ,2) , (3,4), (5,9)) a[:][1] # (3, 4) # slicing t1[:-1] # (1, 2, 'a') t1[1:..