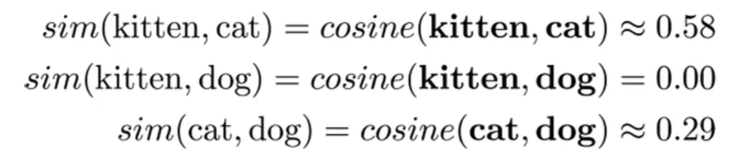이 파트에서는 cs231n의 자료를 가지고 소개를 해볼 예정이다. cs231n에는 deep learning 을 이용하여 vision 분야에 접근하는 내용을 다루고 있다. visual recognition에는 image, 3D modeling, Grouping, segmentation 의 내용이 있지만 CS231n에서는 image classification에 중점을 두고 강의를 진행한다. 이렇게 이미지를 Local한 지역에 물체를 탐지하는 것을 Object Detection 이라고 하며, 그런 Object가 무엇인지 어떤 행동을 취하는지 Caption을 달아주는 것을 image Captioning 이라고 한다. 이 강의는 image에 대해 상세하게 다룰 예정이다. Vision 분야는 이미지를 탐지하고 분석..