[NLP] Pointwise Mutual Information (PMI) 전통적인 자연어처리 방식에서는 동시발생 행렬(Co-occurrence Matrix), 즉, 각 단어가 동시에 출현한 빈도를 측정한 행렬을 사용하였다. 그러나, 발생 횟수를 기반으로 하기 때문에 많이 출현하는 The, A, An 등과 같은 단어로 인해 해당 단어와의 유사도가 높게 측정될 수 있다. 이와 같은 문제를 해결하고자 점별 상호정보량(Pointwise Mutual Information, PMI)이라는 척도가 도입된다. PMI(x,y)=log2P(x,y)P(x)⋅P(y) P(x)는 x가 발생할 확률, P(y)는 y가 발생할 확률, P(x,y)=P(x∩y)는 x와 y가 동시에 발생할 확률을 의미한다. 이때 PMI 값이 .. Deep Learning/Natural Language Processing 2023.04.03
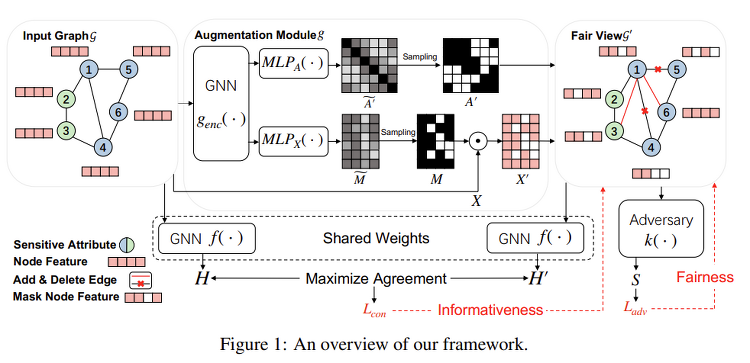
Learning Fair Graph Representations via Automated Data Augmentations (ICLR'23) Contents 기존 Data Augmentation 방식은 Heuristic하게 적용하기 때문에 도메인에 따라 성능이 달라진다는 문제점이 존재한다. 본 연구에서는 Fairness-aware한 방식을 통해 Data Augmentation을 수행하는 Graphair 기법을 제안하였다. Introduction Graph Neural Network (GNN) 기법은 Knowledge Graph, Social Media, Molecular Prediction 등과 같은 다양한 분야에서 우수한 성능을 보이고 있다. 그러나, 대부분의 GNN 기법은 인종, 성별 등과 같은 민감한 정보에 따라 다른 예측값을 도출하는 문제가 존재한다. 이와 같은 문제를 해결하고자 Node Feature Masking, Edge Pert.. Paper review/Graph Mining 2023.03.23
STAM: A Spatiotemporal Aggregation Method for Graph Neural Network-based Recommendation (WWW'22) Contents 해당 논문은 기존 추천 관련 연구에서는 주로 Spatial 정보만을 고려하고 Temporal 정보는 고려하지 않는 문제점을 해결하고자, Spatial-Temporal Aggregation Method (STAM) 기법을 제안하였다. Introduction Graph Neural Network (GNN)의 성능이 우수한 것으로 검증된 후 Recommendation 분야에서는 주로 GNN 기법을 기반으로 추천 시스템을 구축하고 있다. Recommendation에 적용된 GNN의 Aggregation Function을 종합하면 1) Mean Pooling, 2) Degree Normalization, 3) Attentive Pooling, 4) Central Node Augmentation 으.. Paper review/Recommender System 2023.03.20
GSL4Rec: Session-based Recommendations with Collective Graph Structure Learning and Next Interaction Prediction (WWW'22) Contents GSL4Rec 기법은 빠르게 변화하는 소셜 네트워크에 적용하기 위해 확장성(Scalability)과 유효성(Effectiveness)이 고려된 기법이다. GSL4Rec 기법은 Coarse Neighbor Screening과 Self-adaptive Graph Sructure Learning 총 2 stage로 구성되어 있다. 또한, 단계별 휴리스틱 방법을 적용하여 더 쉽게 Global Optima에 도달하도록 만들어 효율성을 향상시켰다. Introduction Session-based Recommendation은 Session 안의 사용자의 행동을 기반으로 사용자가 선호하는 것을 예측하는 것을 목표로 한다. 최근에는 사용자 간의 관계 등과 같은 정보를 추가로 고려하는 Session-bas.. Paper review/Recommender System 2023.03.20
CL4CTR: A Contrastive Learning Framework for CTR Prediction (WSDM'23) Contents 본 연구에서는 Self-supervised Learning을 적용한 Model-agnostic 기법인 CL4CTR 기법을 제안한다. CL4CTR 기법은 Contrastive Loss, Feature Alignment, Field Uniformity로 구성되어 있다. Introduction CTR Prediction Task는 제품이 클릭될 확률을 계산하는 Task로 널리 사용되는 Task 중 하나이다. 기존 CTR Prediction의 경우 크게 두 가지로 나눌 수 있다. 1) Traditional Methods (such as Logistic Regression, Factorization Model), 2) Deep-learning Based Methods (such as xDeepFM.. Paper review/Recommender System 2023.03.20
Modeling Spatio-temporal Neighbourhood for Personalized Point-of-interest Recommendation (IJCAI'22) Contents Point-of-interest (POI)는 장소를 추천하는 Task라고 볼 수 있다. 기존 POI 연구에서는 대부분 User와 Location을 따로 분리하여 모델링하고 있으며, 사용자의 장소에 대한 시공간적 수용(Acceptance) 범위를 무시하고 있다. 본 연구에서는 이와 같은 문제를 해결하고자, Knowledge Graph with Temporal information (TKG)를 구성하여 Timestamp와 User, Location을 함께 고려하고자 TKG를 기반으로 한 Spatial-Temporal Graph Convolutional Attention Network (STGCAN) 기법을 제안한다. Introduction POI Recommendation은 사용자가 선호할 .. Paper review/Recommender System 2023.03.19
Enhancing Sequential Recommendation with Graph Contrastive Learning (IJCAI'22) Contents 기존 연구에서 주로 사용하는 Sequential Recommendation은 Local Context Information을 사용하거나 오직 Item Loss만을 사용해서 구축하고 있기 때문에, Sequence Representation을 제대로 학습하지 못한다는 문제점을 언급하며, 이를 해결하기 위해 Weighted Item Transition Graph (WITG)를 사용하는 Graph Contrastive Learning for Sequential Recommendation (GCL4SR) 기법을 제안하는 논문이다. Introduction Sequential Recommendation의 State-of-the-art (SoTA) 모델들은 우수한 성능을 보이고 있으나, 다음과 같은 문.. Paper review/Recommender System 2023.03.19
Scaling Law for Recommendation Models: Towards General-purpose User Representations (AAAI'23) Contents 이미지, 자연어처리 등과 같은 분야에서 BERT, GPT-3, CLIP 등의 대규모 사전 학습 모델의 성능이 우수한 것은 이미 검증되었다. 그러나, User Representation 에서 범용적으로 사용될 수 있는 모델에 대한 연구는 아직 많이 연구되지 않고 있다. 본 연구에서는 Large-Scale User Encoder를 학습함으로써 범용적으로 사용될 수 있는 User Representation 학습이 가능한 Contrastive Learning User Encoder (CLUE)를 제안하였다. Introduction 비전, 음성 등과 같은 분야에서는 Foundation Model이라고 불리는 Large-Scale Model (BERT, GPT-3, CLIP, etc.)이 자주 제안.. Paper review/Recommender System 2023.03.15
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer (CIKM'19) Contents BERT4Rec은 모델명 그대로 BERT를 이용한 Recommendation 모델이다. Sequential 데이터를 다룰 때 주로 사용하는 기법으로, SASRec 다음으로 나온 모델이라고 볼 수 있다. SASRec과 다른 점은 Bidirectional 하다는 점과 Masking 기법을 사용한다는 점이다. Introduction 기존 Sequence 데이터를 다루는 추천 시스템 연구에서는 주로 Recurrent Neural Network (RNN) 과 같은 기법을 사용하여 Encoding한다. 그러나 RNN 기법은 왼쪽에서 오른쪽으로, 즉, 입력으로 들어오는 제품의 순서만을 고려하기 때문에 left-to-right 방식(Undirectional)은 사용자의 표현(Representation).. Paper review/Recommender System 2023.03.14
LightGCL: Simple yet effective graph contrastive learning for recommendation (ICLR'23) Contents LightGCL은 추천 시스템에 그래프와 대조 학습(Contrastive Learning)을 도입한 기법이다. 기존 연구에서 주로 사용하는 대조 학습 방식은 node dropout, edge dropout과 같은 확률적 증강(Stochastic Augmentation) 기법을 사용하거나, 휴리스틱 기반 증강(Heuristic-based Augmentation) 기법을 사용하고 있다. 그러나 이와 같은 방식은 노이즈로 인한 편향(Bias)이 존재하기 때문에 원래 그래프의 의미론적인 구조를 제대로 파악하지 못한다. 이와 같은 문제를 해결하고자 본 연구에서는 간단하지만 효과적이고 강건(Robust)한 기법인 LightGCL 기법을 제안하였다. Introduction 추천 시스템에서 사용되는 G.. Paper review/Recommender System 2023.03.09